
Quelle infrastructure Data pour l'IA? - Guide Complet
De l'idée au chatbot en production. Le guide complet pour construire l'infrastructure Data qui rendra vos agents IA enfin performants. Stack, roadmap et budgets.
INTELLIGENCE ARTIFICIELLE
Iannis Iglesias
10/23/202532 min read


Stack Data pour l'IA : Le guide complet pour passer du POC à la production
Aujourd'hui presque tout le monde comprend que la data est clé pour l'IA.
C'est une observation récurrente dans les échanges avec des start-ups et des PME. Le diagnostic est juste : garbage in, garbage out. L'idée qu'une IA ne produit rien de bon sans données de qualité est désormais acquise.
Le problème ? Peu de personnes savent concrètement ce que signifie avoir des données de qualité en termes d'infrastructure.
Le constat sur le terrain est souvent le suivant : des entreprises testent ChatGPT sur leurs documents internes en pensant avoir "démarré l'IA". Des équipes lancent un chatbot support sans avoir bien préparé leurs données. Résultat : des réponses incohérentes, un projet abandonné en deux mois et la conclusion interne que "l'IA ne marche pas pour nous".
La réalité est plus nuancée. Les outils d'IA (ChatGPT, Agentforce, Dust, n8n..) sont accessibles et fonctionnels. Ce qui ne fonctionne pas, ce sont les données fragmentées dans 15 outils différents sans cohérence. Le CRM ne parle pas à l'outil de support. Les analytics produit sont coupés de la facturation. Personne ne sait où trouver l'historique complet d'un client.
Ce guide existe pour répondre à une question simple : par quoi commencer concrètement pour activer l'IA dans son entreprise ?
L'objectif est de présenter les étapes concrètes pour passer de simples tests ChatGPT à la mise en place d' agents IA en production qui changent votre façon de travailler.
Vous y trouverez :
Les signaux qui indiquent qu'il est temps d'investir (ou qu'on peut encore attendre).
Les 6 briques essentielles d'une infrastructure Data moderne, expliquées simplement.
Les budgets réalistes selon votre taille (40 vs 150 personnes).
Les cas d'usage IA les plus rentables pour démarrer.
Ce guide s'adresse aux dirigeants et responsables techniques ou équivalent de start-ups et PME (40 à 400 personnes) qui visent le déploiement d'agents IA concrets. L'enjeu est de comprendre la bonne infrastructure pour mettre en place des chatbots qui aident réellement le support, des copilotes qui accélèrent les commerciaux, et des assistants qui font gagner du temps au quotidien.
Commençons par le commencement : pourquoi vos outils actuels ne suffiront plus.
I. Le problème qu'on ne voit pas (avant de construire)
Pourquoi Excel, votre CRM et Google Analytics ne suffiront pas
Imaginons une scale-up SaaS de 80 personnes. Croissance solide, équipe tech compétente. L'idée émerge de lancer un copilote commercial pour accélérer le cycle de vente : un agent IA qui analyse le comportement du prospect sur le produit (via Mixpanel ou Google Analytics), croise avec l'historique CRM (Salesforce) et suggère le bon moment et le bon argument pour closer.
Le projet n'avance pas.
Non par manque de compétence mais parce que personne ne peut croiser ces deux sources de données. Mixpanel (ou GA) et Salesforce ne communiquent pas. Les tentatives d'exports manuels génèrent des données obsolètes. Le commercial voit des informations vieilles de 3 jours. L'agent IA, lui, ne voit rien d'utilisable.
Cette situation illustre le problème invisible de la majorité des entreprises en croissance : le SaaS Sprawl (l'étalement des applications SaaS).
Votre CRM (HubSpot, Salesforce...), votre outil de support (Zendesk, Jira ou Intercom), vos analytics (Mixpanel, Google Analytics), votre facturation (Stripe), vos conversations (Slack), votre documentation (Notion)... Au fil des ans, 10, 20, parfois 50 outils SaaS ont été ajoutés.
Chacun est performant dans son silo. Le problème surgit au moment de croiser les informations. Et c'est exactement ce dont l'IA a besoin pour être pertinente.
Les trois problèmes invisibles de vos données actuelles :
Fragmentation : Vos données vivent dans des silos étanches. Obtenir une vision 360 d'un client impose d'ouvrir 5 onglets, de copier-coller des informations et d'espérer que les identifiants correspondent.
Qualité douteuse : Chaque outil a sa propre logique. Un même client peut avoir trois emails différents. Les dates ne correspondent pas. Personne ne sait quelle version est la bonne.
Absence de contexte unifié : Un dashboard BI classique affiche : "Chiffre d'affaires : 150 000€". C'est utile pour un reporting. Mais un agent IA doit savoir : ce client précis a-t-il ouvert un ticket support récemment ? A-t-il utilisé la fonctionnalité X ? Cette richesse de contexte n'existe nulle part.
C'est la différence fondamentale : un dashboard BI agrège des chiffres passés. Un agent IA agit en temps réel sur des contextes complexes.
Pour un dashboard, croiser 2-3 tables suffit. Pour un agent IA efficace, il faut croiser 5 à 10 sources, en temps réel, avec des données non structurées (emails, tickets, PDF...), tout en respectant les droits d'accès.
Une étude Gartner de 2024 estime que les data analysts passent en moyenne 60% de leur temps à préparer les données plutôt qu'à les analyser. Pour 5 jours de travail, 3 sont dédiés à chercher, nettoyer et organiser. C'est 3 jours où aucune valeur n'est créée.
Cette réalité touche particulièrement les entreprises entre 40 et 300 personnes. Vous êtes trop grands pour Excel mais trop petits pour une équipe data de 10 personnes. C'est le moment où la dette technique data commence à freiner la croissance.
L'objection habituelle est : "Notre data analyst fait déjà des exports et des tableaux croisés dynamiques. Ça fonctionne."
Ça fonctionne pour un rapport mensuel. Ça ne fonctionne pas pour détecter qu'un client à forte valeur réduit son usage, ni pour suggérer à un commercial le bon moment pour appeler. Et encore moins pour alimenter un chatbot qui doit répondre en 2 secondes avec des informations actualisées.
Les 3 signaux qui montrent qu'il est temps d'agir
Comment savoir s'il faut investir maintenant dans une infrastructure Data moderne ? Il existe trois signaux clairs. Si vous en reconnaissez au moins deux c'est probablement le moment.
Signal #1 : Vos équipes passent plus de temps à chercher qu'à analyser
Observez votre data analyst (ou la personne qui en tient le rôle). Combien de temps passe-t-elle chaque semaine à :
Chercher où se trouve l'information ?
Exporter des données depuis X outils différents ?
Nettoyer les doublons et corriger les incohérences ?
Croiser manuellement des fichiers Excel ou Google Sheets ?
Si la réponse est "plus de la moitié de son temps", vous avez un problème d'infrastructure, pas de compétence. Vous sous-utilisez un profil qualifié en le cantonnant à de l'ingénierie de survie.
Signal #2 : Vous ratez des opportunités business faute de vision consolidée
Les cas les plus fréquents :
Un client réduit son usage de 40% en deux semaines, mais personne ne le détecte avant le churn (résiliation).
Un prospect chaud demande un devis mais le commercial n'est pas notifié car l'information est coincée dans un formulaire qui ne parle pas au CRM.
Une opportunité d'upsell évidente apparaît dans les données d'usage mais seul le Product Manager la voit (et il n'est pas responsable de la vente).
Un cas fréquent : une entreprise peine à sortir ses métriques clés (rétention, revenu moyen, délai de closing) lors d'une levée de fonds. L'équipe met 5 jours à fiabiliser ces chiffres. Les données existent mais éparpillées. Les investisseurs doutent alors de la capacité de l'équipe à piloter sa croissance.
Signal #3 : Vos premiers tests IA échouent par manque de contexte
C'est le signal le plus révélateur. Vous testez un chatbot pour le support client. Il répond à côté. Vous essayez un copilote commercial. Il propose n'importe quoi.
Le problème n'est pas l'IA. Le problème est que l'IA n'a accès qu'à 20% du contexte nécessaire.
Un chatbot support efficace a besoin de :
La base de connaissances (Notion, Confluence...).
L'historique des tickets similaires (Zendesk, Jira...).
Les informations sur le client (Salesforce, HubSpot...).
Les dernières mises à jour du produit (GitHub, Linear...).
Si ces données sont éparpillées, le chatbot ne peut pas les croiser. Il répond avec 20% du contexte, ce qui génère 80% de réponses insatisfaisantes.
L'objection classique à ce stade : "On est trop petits pour investir dans tout ça."
C'est souvent l'inverse. Une entreprise de 40 personnes qui gagne 30% de productivité sur son équipe support (grâce à un bon chatbot interne) économise l'équivalent d'un recrutement. La vraie question n'est pas "Sommes-nous assez grands pour nous le permettre ?" mais "Pouvons-nous nous permettre d'attendre encore six mois ?"
Deux portraits : la start-up et la PME face à leurs données
Pour rendre les choses concrètes, voici deux profils d'entreprises à deux moments différents de leur croissance.
Portrait #1 : La start-up SaaS (40 personnes)
Contexte : Série A levée il y a 18 mois. Croissance rapide. Ajout constant de nouveaux outils SaaS. 1er data analyst embauché.
Outils typiques : HubSpot, Zendesk, Mixpanel, Google Analytics, Stripe, Notion.
Douleurs : Data analyst passe 3 jours/semaine sur des exports CSV et VLOOKUP. Impossible de détecter le churn à temps (signaux dans Mixpanel, contrats dans HubSpot). Support client lent (info dans 4 outils).
Objectif IA : Chatbot support interne (pour aider l'équipe support) + Copilote commercial (alerter sur les leads chauds).
Contrainte : Budget infrastructure 2-5k€/mois. Pas de data engineer full-time.
Portrait #2 : La PME en croissance (150 personnes)
Contexte : Rentable ou proche de l'être. Structure établie. Dette technique data accumulée sur 5 ans. Équipe data de 2-3 personnes en mode "pompier".
Outils typiques : Salesforce, Jira Service Management, Looker/Tableau, un Data Warehouse (BigQuery ou Snowflake) sous-utilisé, des scripts Python maison.
Douleurs : Chaque département a sa "vérité" sur les chiffres. Conformité RGPD approximative. Projets IA au ralenti faute d'accès sécurisé aux données. Dashboards lents ou faux.
Objectif IA : Agents IA transverses (support, sales, finance) + Self-service BI (questions en langage naturel).
Contrainte : Budget 10-20k€/mois possible mais besoin de gouvernance stricte (RGPD, audit) et de ROI rapide.


vous n'avez pas besoin des ressources d'une grosse boîte. Vous avez besoin d'une infrastructure adaptée à votre taille. Les outils modernes permettent aujourd'hui de construire en 10 semaines ce qui prenait 6 mois il y a trois ans. À condition de savoir quelles briques assembler.
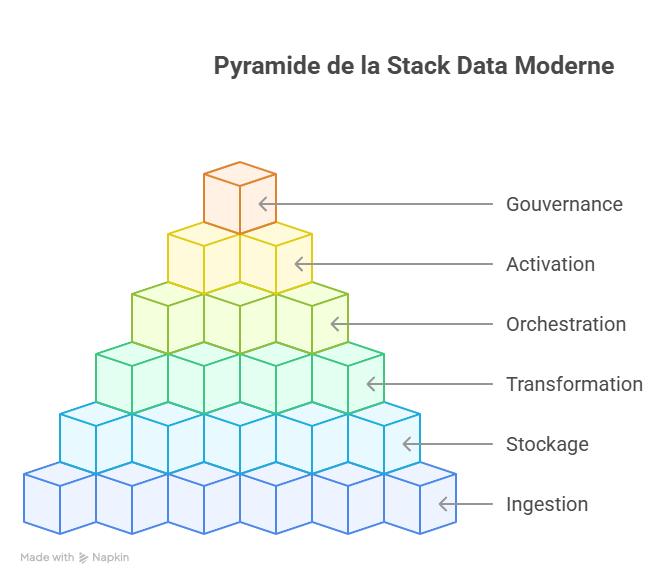
II. La stack Data moderne expliquée simplement
Les 6 briques essentielles (et pourquoi elles existent)
Construire une infrastructure Data moderne ressemble à une chaîne logistique. Chaque brique a un rôle précis. C'est l'ensemble qui crée de la valeur.
Brique 1 : L'ingestion (Collecter)
Rôle : Rapatrier automatiquement les données depuis tous vos outils (CRM, support, analytics, facturation) vers un endroit centralisé.
Analogie : Le service de coursiers qui collecte les colis chez différents fournisseurs et les achemine vers votre entrepôt central. Sans cela vous faites des exports CSV manuels.
Outils clés : Airbyte (open source), Fivetran (solution managée premium) ou les connecteurs natifs des plateformes cloud.
Le concept : On utilise l'approche ELT (Extract, Load, Transform). On extrait les données brutes (Extract), on les charge immédiatement dans l'entrepôt (Load) et ensuite on les transforme (Transform). C'est plus flexible que l'ancienne méthode ETL car le stockage brut ne coûte presque rien et permet de changer d'avis sur les transformations plus tard.
Brique 2 : Le stockage (Centraliser)
Rôle : Stocker toutes vos données de manière organisée, sécurisée et interrogeable. C'est le cœur du système.
Analogie : L'entrepôt central où tout est référencé et accessible rapidement.
Le concept : Le Lakehouse est l'architecture recommandée en 2025. C'est le meilleur des deux mondes : la flexibilité et le faible coût d'un Data Lake (stockage brut) avec la performance et la gouvernance d'un Data Warehouse (optimisé pour l'analyse).
Outils clés :
Start-up : BigQuery (Google Cloud) est un excellent choix (premier To de requêtes gratuit/mois).
PME : Snowflake (très performant, multi-cloud, prise en main rapide) ou Databricks (si vous visez des cas d'usage IA/ML avancés).
Organisation : On utilise l'Architecture Medallion :
Bronze : Données brutes, copie exacte des sources. L'historique immuable.
Silver : Données nettoyées, dédupliquées avec une structure minimale.
Gold : Données transformées pour les usages métier (dashboards, agents IA). C'est la source de vérité.
Brique 3 : La transformation (Rendre exploitable)
Rôle : Nettoyer, structurer, enrichir les données brutes (Bronze/Silver) pour les rendre utilisables (Gold).
Analogie : Le chef qui transforme des ingrédients bruts en plats prêts à servir.
L'outil incontournable : dbt (Data Build Tool). C'est devenu le standard de facto. Avant dbt les analystes écrivaient des scripts SQL éparpillés. dbt apporte les practices du développement logiciel à la data : versionning (Git), tests automatisés (cette colonne est-elle unique ?) et documentation.
Pourquoi c'est crucial pour l'IA : Sans transformation rigoureuse, l'agent IA travaille avec des données sales, mélange les clients et perd toute crédibilité.
Brique 4 : L'orchestration (Automatiser)
Rôle : Planifier et surveiller l'exécution de tous les flux de données.
Analogie : Le chef d'orchestre qui coordonne tous les musiciens.
En pratique : Chaque nuit à 2h, l'orchestrateur lance : 1. L'ingestion (Airbyte) -> 2. La transformation (dbt) -> 3. Le rafraîchissement des dashboards et des index IA.
Outils clés : Dagster (moderne, intuitif), Prefect ou Airflow (plus ancien, très robuste mais complexe).
Brique 5 : L'activation (Servir la donnée)
Rôle : Servir les données aux utilisateurs finaux. C'est la brique qui crée de la valeur visible.
Sous-catégorie 1 : BI / Analytics
Outils : Metabase (open source, idéal pour start-ups), Looker (Google), Tableau ou Power BI.
Sous-catégorie 2 : IA / Agents
C'est ici que ça devient spécifique. Pour qu'un agent IA soit efficace, il a besoin de composants dédiés :
Modèles d'Embeddings : Pour créer les représentations vectorielles des textes (ex: modèles d'OpenAI, Sentence Transformers via Hugging Face, modèles Mistral).
Base Vectorielle (Vector Database) : Pour stocker ces embeddings et les interroger rapidement (ex: Pinecone, Weaviate ou pgvector pour démarrer).
RAG (Retrieval-Augmented Generation) : La technique qui permet à l'agent de récupérer les bons documents avant de générer sa réponse.
Brique 6 : La Gouvernance (Sécuriser et Fiabiliser)
Rôle : Assurer que l'ensemble de la stack est fiable, sécurisé et conforme. C'est la couche transverse qui garantit la confiance.
Analogie : Le service de sécurité et de contrôle qualité de l'entrepôt. Il vérifie qui a le droit d'entrer, s'assure que les produits sont conformes et protège contre le vol.
Le concept : Cette brique inclut la gestion des accès (RGPD, RLS), la qualité des données (monitoring) et la découverte (catalogue).
Outils clés : Bien que les entrepôts comme Snowflake ou BigQuery offrent des fonctions natives (ex: RLS, masquage), des outils spécialisés existent pour industrialiser cette brique :
Catalogue & Découverte : Atlan, DataHub, Castor (français).
Qualité & Observabilité : Monte Carlo, Soda.
Contrôle d'accès : Immuta, Privacera.
Pourquoi c'est crucial : Sans gouvernance, votre stack data est une machine incontrôlable. L'IA pourrait exposer des données sensibles ou se baser sur des chiffres faux. C'est une fondation non-négociable qui sera détaillée dans la partie V.
Focus IA : pourquoi c'est différent de la BI classique
Un dashboard Looker fonctionnel ne suffit pas pour l'IA. Les besoins techniques ne sont pas les mêmes.
Différence #1 : Besoin de contexte multi-sources
BI : Agrège 2-3 tables (ex: Ventes + Clients = CA par secteur).
IA : Doit croiser 5-10 sources en temps réel (ex: CRM + Usage Produit + Tickets Support + Emails) pour suggérer une action à un commercial.
Différence #2 : Données non structurées
BI : Traite des données structurées (tableaux, chiffres, dates).
IA : Travaille majoritairement avec du non structuré (PDF, emails, tickets support, conversations Slack). Pour les exploiter, il faut les transformer en embeddings (vecteurs numériques) et les stocker dans une base vectorielle.
Différence #3 : Temps réel et sécurité
BI : Un retard de 24h sur les données est souvent acceptable.
IA : Doit agir sur des données fraîches et respecter scrupuleusement les droits d'accès. Le commercial France ne doit voir que les données France. Cette sécurité au niveau ligne (RLS - Row-Level Security) doit s'appliquer en temps réel à chaque requête de l'agent.
Le concept de RAG expliqué simplement
RAG = Retrieval-Augmented Generation (Génération Augmentée par Récupération)
C'est la technique qui permet à un LLM (comme ChatGPT ou Claude) de répondre avec vos données au lieu d'inventer.
Sans RAG : Vous posez une question à ChatGPT. Il répond en se basant sur sa mémoire d'entraînement (données publiques jusqu'en 2024). Il n'a pas accès à vos documents internes. Risque élevé d'hallucination.
Avec RAG :
Votre question est transformée en vecteur.
Le système cherche dans votre base vectorielle (qui contient vos PDF, tickets, etc.) les 5-10 documents les plus pertinents.
Ces documents sont injectés en contexte dans le prompt envoyé au LLM.
Le LLM génère sa réponse en se basant uniquement sur ces documents.
Résultat : Des réponses exactes, basées sur vos données internes, avec traçabilité (l'IA peut citer ses sources). C'est ce qui transforme un gadget en un assistant fiable.
Exemple concret :
Question (Sans RAG) : "Quel est le délai de préavis pour résilier un contrat Premium ?"
Réponse ChatGPT : "Généralement, les délais de préavis sont de 30 ou 90 jours mais cela dépend des termes spécifiques de votre contrat." (Inutile, générique).
Question (Avec RAG, accès à vos CGV) : "Quel est le délai de préavis pour résilier un contrat Premium ?"
Réponse : "Le délai de préavis pour un contrat Premium est de 60 jours avant la date d'anniversaire, conformément à l'article 12.3 de nos Conditions Generales de Vente."
Source : CGV_2024.pdf
La différence est massive.

Les 3 architectures possibles (et comment choisir)
Une fois les briques comprises, reste à choisir l'architecture adaptée. Il existe trois approches principales. Chacune correspond à un contexte, un budget et un niveau de maturité différents.
Architecture 1 : Plateforme tout-en-un (Agentforce, Dust, Microsoft Copilot...)
C'est la solution la plus rapide à déployer. Vous utilisez une plateforme qui intègre données, IA et interfaces dans un seul environnement.
Quand c'est LA bonne option (et vous devriez foncer) :
✅ Votre CRM est votre source de vérité : Si 70-80% de vos données critiques sont déjà dans Salesforce ou HubSpot (clients, deals, tickets, historique), cette architecture est parfaite. Pas besoin de construire une stack Data externe.
✅ Cas d'usage "standards" : Vous voulez un chatbot support qui répond sur la base de vos articles Salesforce Knowledge, un copilote commercial qui suggère des next steps dans les opportunités, un assistant qui résume les emails. Tous ces cas sont natifs dans Agentforce.
✅ Pas d'équipe data : Vous n'avez ni data engineer ni data analyst senior capable de monter une stack dbt + BigQuery. Vous voulez déléguer la complexité technique.
✅ Besoin de rapidité : Vous visez une mise en prod en 4-6 semaines, pas en 12 semaines.
Exemple concret où ça marche parfaitement :
PME de conseil 100 personnes. Salesforce CRM structuré depuis 5 ans. Tous les deals, contacts, tickets support et contrats sont dedans. Ils veulent un copilote sales qui suggère aux commerciaux quand relancer un prospect et avec quel argument.
→ Solution : Agentforce + Data Cloud
→ Timeline : 8-10 semaines
→ Coût : 6 000€/mois tout compris
→ Résultat : Fonctionnel, ROI rapide, équipe ravie
Quand ça devient limitant (et il faut passer sur l'architecture modulaire) :
❌ Vos données critiques sont ailleurs : Si vos données produit sont dans Mixpanel, vos tickets dans Intercom (hors Service Cloud), votre facturation dans Stripe et votre documentation dans Notion, il faut rapatrier tout ça dans Salesforce. Deux options :
Via Data Cloud + connecteurs : comptez 2 000 à 4 000€/mois supplémentaires + complexité de setup
Via MuleSoft (outil d'intégration Salesforce) : ça monte vite à 20-30K€/an juste pour les connecteurs
→ À ce stade, une stack modulaire (BigQuery + Airbyte) vous coûte 2 fois moins cher et vous garde flexible.
❌ Cas d'usage très spécifiques : Vous voulez construire un système de recommandation ML custom sur le comportement produit, ou un agent qui analyse des vidéos de démos commerciales, ou un chatbot qui répond en s'appuyant sur des règles métier complexes que vous devez coder vous-même.
→ Les plateformes tout-en-un excellent sur les 80% de cas d'usage standard. Pour les 20% custom, vous serez bloqué ou obligé de hacker la plateforme.
❌ Coût scaling : Agentforce se facture par utilisateur (~50-100€/utilisateur/mois selon les fonctionnalités). Si vous avez 150 utilisateurs qui utilisent l'agent IA, ça monte vite à 10-15K€/mois. Une stack modulaire avec une API OpenAI coûterait 3-5K€/mois pour le même usage.
❌ Souveraineté / contrôle : Vous êtes dans un secteur régulé (santé, finance) et vous devez garantir que les données ne sortent jamais d'un cloud européen spécifique. Ou vous voulez utiliser un LLM français (Mistral) pour des raisons de souveraineté.
→ Avec Agentforce, vous êtes dépendant de l'infrastructure Salesforce et des LLM qu'ils ont intégrés (OpenAI/Anthropic via Einstein). Vous ne pouvez pas brancher un autre LLM.
Exemple concret où ça coince :
Start-up SaaS 80 personnes. Salesforce CRM pour les deals, mais :
Données produit dans Mixpanel (features utilisées, engagement)
Tickets support dans Intercom
Documentation dans Notion
Analytics marketing dans Google Analytics
Ils veulent un copilote commercial qui suggère des upsells en croisant CRM + usage produit + tickets support.
→ Avec Agentforce : il faut rapatrier Mixpanel, Intercom et Notion dans Salesforce via Data Cloud. Setup complexe, coût élevé, vendor lock-in.
→ Avec stack modulaire (BigQuery + Airbyte + dbt) : on connecte les 4 sources en 2 semaines, on croise les données, on sert le copilote via une API. Coût 3 fois moindre, flexibilité totale.
Budget indicatif : 3 000 à 8 000€/mois pour une PME 80 personnes (incluant Data Cloud + Agentforce + licences)
Architecture 2 : Stack modulaire cloud (BigQuery + dbt + Airbyte + Pinecone)
C'est l'architecture recommandée pour les entreprises qui veulent garder le contrôle et évoluer sans se bloquer. Vous assemblez des briques best-in-class, chacune excellente dans son domaine.
Quand choisir : Vos données vivent dans plusieurs outils SaaS (CRM, support, analytics, facturation). Vous voulez activer plusieurs cas d'usage IA (chatbot support, copilote commercial, dashboards métier) sans dépendre d'un seul vendor.
Avantages :
Flexibilité maximale : vous pouvez changer une brique sans tout reconstruire
Coût maîtrisé : vous payez l'usage réel (pas de licence par utilisateur)
Compatible avec tous les LLM (OpenAI, Anthropic, Mistral)
Limites :
Nécessite un data analyst + un développeur back-end (ou un data engineer dès 80 personnes)
Courbe d'apprentissage initiale sur dbt et l'orchestration
Budget indicatif :
Start-up 40 pers : 500 à 2 000€/mois (BigQuery gratuit jusqu'à 1 To de requêtes + dbt Core gratuit + Metabase open source + pgvector gratuit)
PME 150 pers : 3 000 à 6 000€/mois (Snowflake + dbt Cloud + Pinecone managé)
Architecture 3 : Hybride (CRM/ERP + Stack Data externe)
Vous conservez votre plateforme métier principale (Salesforce, SAP) pour les processus transactionnels, mais vous construisez une stack Data parallèle pour agréger, enrichir et servir les données aux agents IA.
Quand choisir : Vous avez déjà un CRM ou ERP lourd avec des années d'historique. Rapatrier toutes les données serait trop coûteux. Mais vous avez besoin de croiser ces données avec d'autres sources (analytics, support, produit).
Avantages :
Meilleur des deux mondes : continuité opérationnelle + flexibilité IA
Vous n'êtes pas obligé de migrer toutes vos données
Limites :
Complexité accrue (deux environnements à maintenir)
Nécessite des connecteurs robustes (Fivetran, MuleSoft) pour synchroniser
Budget indicatif : 5 000 à 12 000€/mois (licences CRM + stack Data + connecteurs)
Budget réaliste : ce qu'il faut prévoir
Les budgets varient énormément selon la taille et l'ambition. Voici une grille réaliste pour éviter les mauvaises surprises.
Start-up 40 personnes (stack modulaire minimale)
Objectif : Premier chatbot support interne + dashboards BI basiques
Stack recommandée :
Ingestion : Airbyte Cloud (gratuit jusqu'à 5 connecteurs)
Stockage : BigQuery (1 To gratuit/mois)
Transformation : dbt Core (gratuit)
Orchestration : Dagster Cloud (gratuit jusqu'à 10 pipelines)
BI : Metabase open source (gratuit, hébergement 50€/mois)
IA : pgvector (gratuit) + OpenAI API (~300€/mois pour un chatbot interne)
Coût total mensuel : 500€ à 1 500€/mois
Coût setup initial : 0 à 5 000€ si vous avez un data analyst compétent en interne. Sinon, prévoir un accompagnement externe (10 à 20K€ pour 6 semaines).
PME 150 personnes (stack managée)
Objectif : Chatbot support client externe + copilote commercial + dashboards métier
Stack recommandée :
Ingestion : Fivetran (2 000€/mois pour 10+ connecteurs)
Stockage : Snowflake (~1 500€/mois pour usage moyen)
Transformation : dbt Cloud (1 000€/mois, 10 développeurs)
Orchestration : Prefect Cloud (500€/mois)
BI : Looker ou Metabase Cloud (1 500€/mois pour 50 utilisateurs)
IA : Pinecone managé (700€/mois) + OpenAI API (~1 500€/mois pour usage intensif)
Coût total mensuel : 6 000 à 10 000€/mois
Coût setup initial : 20 à 40K€ (incluant data engineer freelance 3 mois + mise en place gouvernance RGPD)
Les coûts cachés à anticiper
Au-delà des licences outils, trois postes de dépenses sont souvent sous-estimés :
Formation et montée en compétence : Budget 5 à 10K€/an pour former votre équipe (dbt, orchestration, RAG)
Évolution des volumétries : Les coûts de stockage et compute augmentent avec vos données. Une croissance de 50% du CA peut multiplier par 2 la facture cloud. Prévoir une marge de 30% sur les estimations initiales.
Maintenance et optimisation : Un data engineer (junior) coûte 45 à 55K€/an. Un senior : 65 à 85K€/an. À partir de 80-100 personnes, ce profil devient nécessaire pour éviter la dette technique.
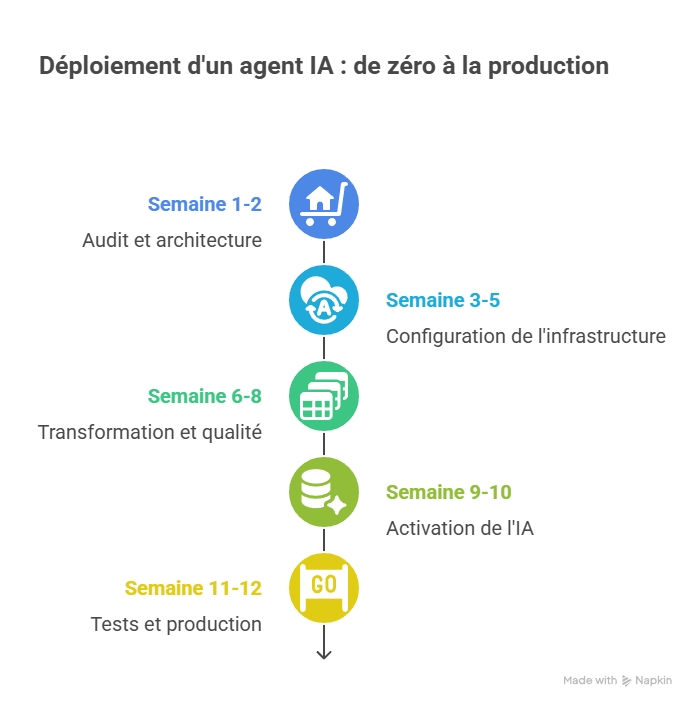
IV. Timeline de mise en œuvre
Combien de temps faut-il pour passer de zéro à un premier agent IA en production ? Voici une timeline réaliste, basé sur des dizaines de projets pour un cas simple.
Semaine 1-2 : Audit et architecture
Actions :
Inventaire complet des sources de données (CRM, support, analytics, facturation)
Cartographie des données personnelles (PII) pour la conformité RGPD
Choix de l'architecture (tout-en-un vs stack modulaire)
Validation du premier cas d'usage IA (chatbot, copilote, dashboard)
Livrables :
Schéma d'architecture validé
Budget détaillé
Registre RGPD initial
Semaine 3-5 : Setup infrastructure
Actions :
Configuration data warehouse (BigQuery ou Snowflake)
Mise en place ingestion (Airbyte : connexion aux 5-10 sources prioritaires)
Création des premières tables Bronze (données brutes)
Setup orchestration (Dagster ou Prefect)
Livrables :
Données brutes accessibles dans le warehouse
Premiers pipelines d'ingestion opérationnels
Dashboard de monitoring des pipelines
Semaine 6-8 : Transformation et qualité
Actions :
Modélisation dbt : création des tables Silver (nettoyées) et Gold (métier)
Tests de qualité automatisés (unicité, non-nullité, cohérence)
Documentation automatique des tables
Mise en place RLS (Row-Level Security) pour protéger les données sensibles
Livrables :
Données transformées et fiables disponibles en Gold
Documentation data générée automatiquement
Tests de qualité qui tournent chaque nuit
Semaine 9-10 : Activation IA
Actions :
Génération des embeddings (transformation des documents en vecteurs)
Setup base vectorielle (Pinecone ou pgvector)
Implémentation RAG (Retrieval-Augmented Generation)
Intégration LLM (OpenAI, Anthropic ou Mistral)
Tests du chatbot avec données réelles
Livrables :
Chatbot en version beta interne
Réponses basées sur vos données, pas d'hallucination
Traçabilité des sources citées
Semaine 11-12 : Tests et production
Actions :
Tests utilisateurs (10-20 personnes en interne)
Ajustement des prompts selon les retours
Formation des équipes (support, commercial)
Mise en production progressive (soft launch)
Livrables :
Agent IA en production sur un périmètre limité
Documentation utilisateur
Plan de monitoring (KPI : taux de résolution, satisfaction, temps de réponse)
Ce qui peut ralentir (et comment l'éviter) :
Problème #1 : Qualité des données sources
Si vos données CRM ou support sont sales (doublons, champs vides, incohérences), il faudra ajouter 2-3 semaines de nettoyage. Solution : Commencer par un audit qualité dès la semaine 1.
Problème #2 : Périmètre mal défini
Les projets qui échouent sont ceux qui veulent tout faire d'un coup. Un chatbot qui répond à 100 questions différentes mettra 6 mois à livrer. Solution : Viser 10 questions clés, puis itérer.
Problème #3 : Attente de la perfection
Un agent IA à 80% de précision en semaine 10 vaut mieux qu'un agent à 95% en semaine 20. Solution : Lancer en beta interne rapidement, améliorer au fil de l'usage.
Timeline réaliste : combien de temps ça prend vraiment
La question revient systématiquement : combien de temps faut-il pour passer de zéro à un agent IA en production ?
La réponse dépend de trois variables : la qualité de vos données de départ, la complexité du cas d'usage et les ressources disponibles (équipe interne ou prestataire).
Scénario optimiste : 10 à 12 semaines
Conditions :
Données déjà bien structurées (CRM propre, documentation centralisée)
Cas d'usage simple (chatbot support avec base de connaissances limitée)
Équipe dédiée (1 data engineer + 1 développeur ou prestataire expérimenté)
Stack moderne déjà en place (BigQuery ou Snowflake existant)
Coût estimé : 15 000 à 25 000€ (stack + prestation ou salaires internes)
Scénario réaliste : 14 à 18 semaines
Conditions :
Données moyennement structurées (quelques incohérences à nettoyer)
Cas d'usage moyen (copilote commercial avec intégration CRM + analytics)
Équipe mixte (data analyst interne + prestataire externe)
Besoin de construire l'infrastructure de zéro
Coût estimé : 30 000 à 50 000€
Scénario complexe : 20 à 26 semaines
Conditions :
Données fragmentées et de qualité variable (nettoyage lourd nécessaire)
Cas d'usage avancé (assistant closing avec intégration multi-sources et personnalisation avancée)
Pas d'équipe data existante (recrutement ou formation nécessaire)
Contraintes réglementaires fortes (secteur bancaire, santé)
Timeline :
Semaine 1-4 : Audit approfondi, recrutement ou montée en compétence
Semaine 5-12 : Construction infrastructure complète avec gouvernance renforcée
Semaine 13-20 : Développement et tests multiples
Semaine 21-24 : Validation conformité et sécurité
Semaine 25-26 : Déploiement progressif et documentation
Coût estimé : 60 000 à 100 000€
Un data warehouse complet peut prendre entre 3 et 12 mois selon la complexité et le périmètre. Mais pour activer un premier cas d'usage IA, vous n'avez pas besoin d'un data warehouse exhaustif. Vous avez besoin d'une infrastructure minimale qui couvre les 3 à 5 sources critiques pour votre agent IA.
C'est la différence entre un projet data traditionnel (tout construire avant de livrer) et une approche moderne (livrer rapidement un premier cas d'usage puis enrichir progressivement).

V. GOUVERNANCE & SÉCURITÉ RGPD
Pourquoi la RGPD est votre alliée (pas votre ennemie)
La RGPD effraie. Le sujet est complexe, les sanctions sont lourdes et personne ne veut se retrouver dans le viseur de la CNIL.
Pourtant, la RGPD bien appliquée n'est pas un frein. C'est un garde-fou qui protège votre entreprise de risques bien réels : fuite de données, usage abusif par des agents IA non contrôlés, perte de confiance clients. La bonne nouvelle : vous n'avez pas besoin d'être expert juridique pour démarrer. Trois principes appliqués dès la semaine 1 suffisent pour avancer sereinement.
Les 3 principes à appliquer tout de suite
Principe #1 : Cartographiez vos données personnelles (PII)
Quoi : Identifier tous les champs contenant des informations personnelles (nom, prénom, email, téléphone, adresse IP, identifiants clients).
Pourquoi : Vous ne pouvez pas protéger ce que vous ne voyez pas. La cartographie est la base de toute conformité.
Comment : Créez un tableur simple avec 6 colonnes :
Source de données (CRM, support, analytics...)
Table ou fichier
Champ (ex: customer_email)
Type de PII (email, téléphone, nom...)
Base légale (consentement, contrat, intérêt légitime)
Durée de conservation (3 ans après dernier contact, 1 an après résiliation...)
Action immédiate : Bloquer 2 heures avec votre data analyst ou développeur pour lister les 20 tables principales. Vous pouvez compléter progressivement.
Exemple concret : Une start-up SaaS identifie que son CRM HubSpot contient 8 champs PII, son outil de support Zendesk en contient 5 et son Google Analytics stocke des IP. Elle liste tout dans un Google Sheet partagé avec son DPO (délégué à la protection des données).
Principe #2 : Appliquez le principe du moindre privilège (RLS)
Quoi : Chaque utilisateur (humain ou agent IA) ne doit voir QUE les données qui le concernent. Un commercial ne doit pas voir les données d'un autre commercial. Un agent IA du support ne doit pas accéder aux données financières.
Pourquoi : Limiter l'accès réduit les risques en cas de fuite ou d'erreur. C'est aussi une obligation RGPD.
Comment : Utilisez le Row-Level Security (RLS) directement dans votre data warehouse. BigQuery, Snowflake et Databricks permettent de créer des vues filtrées par rôle. Exemple :
Vue "sales_team_france" : filtre automatique sur région = France
Vue "support_tier1" : filtre automatique sur tickets non sensibles
Vue "finance_restricted" : accès limité aux 3 personnes autorisées
Action immédiate : Créer 3 vues de base (sales, support, analytics) avec filtres natifs. Durée : 1 heure.
Exemple concret : Une PME 120 personnes configure 5 vues dans Snowflake : une par département (commercial, support, produit, finance, direction). Chaque agent IA est connecté à la vue correspondante. Un agent commercial ne peut jamais accéder aux données financières.
Principe #3 : Tracez tout, masquez par défaut
Quoi :
Logger tous les accès aux données sensibles (qui a consulté quoi et quand)
Masquer les PII par défaut sauf autorisation explicite
Pourquoi : En cas de contrôle CNIL ou d'incident de sécurité, vous devez pouvoir prouver qui a accédé à quelles données. Le masquage limite les risques d'exposition accidentelle.
Comment :
Activer les audit logs de votre data warehouse (gratuit, un clic dans BigQuery ou Snowflake)
Implémenter le masquage dynamique : email → i***@example.com, téléphone → 0645, nom → J*
Créer des rôles "lecture masquée" et "lecture complète" selon les besoins
Action immédiate : Activer les audit logs maintenant (5 minutes). Configurer le masquage pour les 5 champs PII les plus sensibles (1 heure).
Exemple concret : Une scale-up e-commerce active les logs BigQuery. Trois mois plus tard, elle détecte qu'un prestataire externe a téléchargé une table contenant des emails clients sans autorisation. Elle peut tracer précisément l'incident, identifier la source et corriger immédiatement. Sans les logs, elle n'aurait jamais su.
Checklist "Conformité RGPD Sprint 1" (4 semaines)
Semaine 1 :
□ Cartographier les 10 principales sources de données
□ Identifier les champs PII dans chaque source
□ Rédiger la base légale pour chaque traitement
Semaine 2 :
□ Activer les audit logs du data warehouse
□ Créer 3 vues avec Row-Level Security
□ Tester les accès avec 2 utilisateurs tests
Semaine 3 :
□ Implémenter le masquage dynamique sur 5 champs sensibles
□ Documenter les flux de données (qui accède à quoi)
□ Rédiger une politique de conservation (durées par type de donnée)
Semaine 4 :
□ Former l'équipe sur les bonnes pratiques RGPD (1 heure suffit)
□ Valider la conformité avec un DPO ou avocat spécialisé
□ Créer une procédure de réponse aux demandes d'accès (délai légal : 1 mois)
Ces trois principes ne couvrent pas 100% de la RGPD, mais ils couvrent 80% des risques pour démarrer sereinement. Le reste peut être affiné progressivement avec un DPO ou un cabinet spécialisé.
Checklist "Conformité RGPD Sprint 1" (4 semaines)
Semaine 1 : □ Cartographier les 10 principales sources de données □ Identifier les champs PII dans chaque source □ Rédiger la base légale pour chaque traitement
Semaine 2 : □ Activer les audit logs du data warehouse □ Créer 3 vues avec Row-Level Security □ Tester les accès avec 2 utilisateurs tests
Semaine 3 : □ Implémenter le masquage dynamique sur 5 champs sensibles □ Documenter les flux de données (qui accède à quoi) □ Rédiger une politique de conservation (durées par type de donnée)
Semaine 4 : □ Former l'équipe sur les bonnes pratiques RGPD (1 heure suffit) □ Valider la conformité avec un DPO ou avocat spécialisé □ Créer une procédure de réponse aux demandes d'accès (délai légal : 1 mois)
Ces trois principes ne couvrent pas 100% de la RGPD, mais ils couvrent 80% des risques pour démarrer sereinement. Le reste peut être affiné progressivement avec un DPO ou un cabinet spécialisé.
En février 2025, la CNIL a publié des recommandations spécifiques sur l'application du RGPD aux systèmes d'intelligence artificielle. Deux fiches pratiques détaillent comment informer les personnes concernées et faciliter l'exercice de leurs droits dans le contexte IA. Consulter ces ressources dès maintenant vous fera gagner du temps.
CONCLUSION + RESSOURCES
Par où commencer dès demain
Vous avez maintenant une vision claire de ce qu'implique la construction d'une infrastructure Data moderne pour activer l'IA. Vous n'avez pas besoin de tout construire pour commencer. Mais vous avez besoin de décider si c'est le bon moment.
Étape 1 : Diagnostiquez votre maturité
Utilisez cette checklist pour évaluer si vous devez investir maintenant :
□ Mon équipe passe plus de 40% de son temps à chercher ou préparer les données
□ J'ai raté des opportunités business par manque de visibilité (churn non détecté, upsell manqué, leads perdus)
□ Mes premiers tests IA échouent par manque de contexte
□ Mes données sont éparpillées dans plus de 5 outils SaaS
□ Je ne peux pas sortir mes KPI clés en moins de 48 heures
□ Ma conformité RGPD est approximative
□ Je veux activer des agents IA d'ici 6 mois
→ Si vous cochez 3 cases ou plus : Oui, c'est le moment d'investir.
Étape 2 : Choisissez votre premier cas d'usage IA
Ne commencez pas par tout. Commencez par le cas d'usage qui apporte le plus de valeur rapidement :
Chatbot support interne : ROI rapide, adoption facile, risque faible
Copilote SDR : impact commercial direct, gain de productivité mesurable
Assistant closing : libère du temps pour vos meilleurs commerciaux
Critères de choix :
Impact métier mesurable (gain de temps, économies, revenus additionnels)
Données déjà disponibles (ou facilement accessibles)
Sponsor interne motivé (quelqu'un qui portera le projet)
Étape 3 : Auditez vos données actuelles
Avant de construire quoi que ce soit, faites l'inventaire :
Listez vos 5 à 10 sources de données principales (CRM, support, analytics, facturation...)
Identifiez les données personnelles (PII) dans chaque source
Évaluez la qualité (doublons, champs vides, incohérences)
Estimez le volume (nombre de lignes, poids des données)
Durée : 1 journée avec votre data analyst ou un prestataire.
Étape 4 : Décidez de votre approche
Deux options principales :
Option A : Plateforme intégrée (Agentforce, Dust, Microsoft Copilot...)
Avantages : Rapidité, pas besoin de construire l'infrastructure, support inclus
Inconvénients : Coût plus élevé à long terme, moins de flexibilité, dépendance au vendor
Quand choisir : Vous avez moins de 50 personnes, vos données sont déjà dans l'écosystème (Salesforce, Microsoft), vous voulez un résultat en 6-8 semaines
Option B : Stack custom (BigQuery/Snowflake + dbt + Airbyte + OpenAI/Anthropic)
Avantages : Flexibilité totale, coût maîtrisé à long terme, pas de vendor lock-in
Inconvénients : Temps de setup plus long, compétences techniques requises
Quand choisir : Vous avez plus de 50 personnes, vos données viennent de multiples sources, vous voulez garder le contrôle total
Étape 5 : Identifiez vos ressources
Trois configurations possibles :
Config 1 : Full interne
Profils : 1 data engineer + 1 data analyst + 1 développeur
Avantages : Connaissance métier, réactivité
Inconvénients : Montée en compétence nécessaire, mobilisation de ressources
Budget : Salaires + stack (2-5k€/mois)
Config 2 : Hybride (interne + prestataire)
Profils : 1 data analyst interne + prestataire spécialisé
Avantages : Expertise externe, transfert de compétences
Inconvénients : Coordination nécessaire
Budget : 20-40k€ pour setup + 2-5k€/mois de stack
Config 3 : Full externe
Profils : Cabinet spécialisé ou freelance senior
Avantages : Rapidité, pas de recrutement
Inconvénients : Coût initial plus élevé, dépendance
Budget : 40-80k€ pour setup + 2-5k€/mois de stack
L'essentiel n'est pas d'avoir la configuration parfaite. L'essentiel est de commencer maintenant avec les ressources disponibles.
Récapitulatif : vos 3 prochaines actions
Cette semaine : Faites le diagnostic de maturité (checklist ci-dessus) et identifiez votre premier cas d'usage prioritaire
Semaine prochaine : Auditez vos 5 sources de données principales et listez les PII
Sous 1 mois : Lancez un POC (proof of concept) de 2-3 semaines avec un périmètre limité pour valider la faisabilité
La transformation digitale ne se fait pas en un jour. Mais elle commence par une première décision.
Ressources pour aller plus loin
Vous n'êtes pas seuls. Des ressources excellentes existent pour chaque étape de votre projet.
Apprendre les fondamentaux (gratuit)
Podcast DataGen : Les stratégies data des plus belles boîtes en France (BlaBlaCar, Doctolib, Decathlon...). Plus de 200 épisodes sur les architectures modernes, les cas d'usage IA et les retours d'expérience concrets. Animé par Robin Conquet.
Newsletter Blef.fr : Christophe Blefari décrypte chaque semaine les tendances data et IA. L'une des ressources les plus citées par les leaders data en France.
dbt Learn : Cours gratuits officiels sur la transformation de données avec dbt. Indispensable si vous utilisez dbt Core ou dbt Cloud.
Documentation officielle Airbyte : Guides complets pour configurer vos connecteurs d'ingestion. Airbyte est open source et très bien documenté.
Documentation BigQuery / Snowflake / Databricks : Tutoriels officiels pour démarrer avec ces data warehouses. BigQuery propose un tier gratuit jusqu'à 1 To de requêtes par mois.
Remerciements
Mention spéciale au podcast DataGen pour son travail de vulgarisation exceptionnel qui rend la data accessible à tous. Une grande partie des exemples et bonnes pratiques de cet article s'inspire des retours d'expérience partagés par les leaders data invités sur son podcast.
FAQ TECHNIQUE
Q1 : Agentforce nécessite-t-il une stack Data externe ?
Non, Agentforce fonctionne nativement avec les données Salesforce. Si vos données critiques (support, analytics, facturation) sont déjà dans l'écosystème Salesforce, vous pouvez démarrer directement.
Cependant, si vos données essentielles vivent ailleurs (Google Analytics, Zendesk, Mixpanel, votre propre data warehouse), vous avez deux options :
Les rapatrier dans Salesforce via Data Cloud ou MuleSoft
Construire une intégration externe via Einstein Trust Layer
La plupart des entreprises entre 40 et 150 personnes ont des données éparpillées dans 10+ outils. Dans ce cas, une stack externe (BigQuery + dbt + Airbyte) offre plus de flexibilité et un meilleur contrôle à long terme.
Q2 : Peut-on commencer avec une stack minimale et évoluer ?
Oui, absolument. C'est même recommandé.
Stack minimale pour démarrer (coût < 500€/mois) :
Data warehouse : BigQuery (gratuit jusqu'à 1 To de requêtes/mois, puis ~100-200€/mois)
Ingestion : Airbyte Open Source (gratuit, self-hosted)
Transformation : dbt Core (gratuit)
BI : Metabase Open Source (gratuit, self-hosted)
Vecteurs pour IA : pgvector (gratuit, extension PostgreSQL)
Cette stack couvre 80% des besoins d'une entreprise de 40 personnes. Vous pouvez tenir ainsi pendant 12 à 18 mois.
Migration progressive vers du managé (quand vous atteignez 80-100 personnes) :
Snowflake ou Databricks (meilleure performance et scalabilité)
Airbyte Cloud (moins de maintenance)
dbt Cloud (collaboration facilitée, orchestration intégrée)
Pinecone ou Weaviate (bases vectorielles managées pour l'IA)
Le passage d'une stack open source à une stack managée se fait progressivement, service par service, sans tout reconstruire. C'est l'avantage d'utiliser des outils standards (dbt, Airbyte) plutôt que des solutions propriétaires.
Q3 : Combien de temps avant de voir de la valeur ?
Si le projet est bien exécuté, vous voyez de la valeur rapidement :
6 à 8 semaines : Premier dashboard BI fonctionnel avec vos KPI clés actualisés quotidiennement. Votre équipe arrête de chercher des données dans 5 outils différents.
10 à 12 semaines : Premier agent IA en version beta (chatbot support interne, copilote SDR ou assistant closing). Testable par 10-15 utilisateurs internes pour récolter du feedback.
4 mois : Le ROI commence à se mesurer concrètement :
Économies de temps (votre data analyst passe de 60% de préparation à 20%)
Premiers gains métier (réduction tickets support, augmentation taux de conversion, détection churn anticipée)
Amélioration de la prise de décision (KPI fiables et accessibles)
12 mois : L'infrastructure devient un véritable actif stratégique. Vous avez 3-4 cas d'usage IA en production, une gouvernance claire et une équipe autonome.
Le piège à éviter : attendre 6 mois avant de livrer quoi que ce soit. Privilégiez les livraisons progressives (une source à la fois, un cas d'usage à la fois) pour valider rapidement et ajuster en continu.
Q4 : Faut-il embaucher un data engineer ?
Pas forcément au début.
Pour une entreprise de 40 personnes : Un bon data analyst avec des bases en SQL + un développeur back-end peuvent gérer une stack simple (BigQuery + dbt + Airbyte). Les outils modernes sont conçus pour être accessibles sans expertise pointue en data engineering.
Pour une entreprise de 80-100 personnes : Le data engineer devient utile quand :
Vous gérez plus de 10 sources de données
Vous avez des besoins de temps réel (streaming avec Kafka ou similaire)
Vous voulez faire du machine learning custom (pas juste des agents IA avec des LLM)
Vous devez optimiser les coûts d'infrastructure (FinOps)
Alternative au recrutement : Externaliser à un freelance senior ou un cabinet spécialisé pour le setup initial (10-20k€), puis monter en compétence votre data analyst en interne. Beaucoup de profils data analyst évoluent naturellement vers l'analytics engineering puis le data engineering.
Q5 : Comment éviter le vendor lock-in ?
Le vendor lock-in (dépendance à un fournisseur) est un risque réel. Voici comment le limiter :
Privilégier des formats ouverts :
Parquet ou Delta Lake pour le stockage (lisibles par n'importe quel outil)
dbt pour la transformation (portable entre BigQuery, Snowflake, Databricks, Redshift)
Standard SQL autant que possible (éviter les fonctions propriétaires sauf nécessité)
Choisir des outils avec export facile :
BigQuery, Snowflake et Databricks permettent tous l'export complet de vos données
Airbyte et Fivetran peuvent inverser les flux (extraire depuis votre warehouse vers d'autres outils)
Éviter les solutions 100% propriétaires :
Les plateformes tout-en-un (type Agentforce) créent une dépendance forte
Si vous choisissez ce type de solution, gardez une copie de vos données dans un warehouse externe
En pratique, le vendor lock-in est moins problématique qu'il y a 10 ans. Les outils modernes respectent mieux les standards ouverts. Le vrai risque est de construire toute votre logique métier dans des fonctions propriétaires d'un outil spécifique.
Q6 : Quelle différence entre un data warehouse et un data lake ?
Data warehouse :
Stockage structuré et optimisé pour les requêtes SQL rapides
Données déjà transformées et nettoyées
Usage principal : BI, reporting, analytics, dashboards
Exemples : BigQuery, Snowflake, Redshift
Data lake :
Stockage brut de tout type de données (structuré, semi-structuré, non structuré)
Données telles quelles, sans transformation préalable
Coût de stockage très faible
Usage principal : archivage, machine learning, données non structurées (logs, images, vidéos)
Exemples : Amazon S3, Azure Data Lake, Google Cloud Storage
Lakehouse (la tendance actuelle) :
Combinaison des deux approches
Coût de stockage du data lake + performance des requêtes SQL du data warehouse
Architecture moderne recommandée pour les projets IA (besoin de traiter à la fois des données structurées et non structurées)
Exemples : Databricks (Delta Lake), Snowflake (support Iceberg), BigQuery (BigLake)
Pour un projet IA moderne, le Lakehouse est souvent le meilleur choix. Vous pouvez stocker vos données CRM structurées et vos documents PDF ou transcriptions d'appels au même endroit, puis les interroger facilement.
LEXIQUE INTÉGRÉ
Airbyte : Outil open source d'ingestion de données (ETL/ELT). Créé en France. Permet de connecter 300+ sources (CRM, support, analytics...) vers votre data warehouse.
BigQuery : Data warehouse managé de Google Cloud. Pricing au volume de requêtes. Tier gratuit jusqu'à 1 To de requêtes/mois. Très bon choix pour les petites structures.
Databricks : Plateforme Lakehouse leader du marché, construite sur Apache Spark. Combine data warehouse et data lake avec Delta Lake. Très forte sur l'IA et le machine learning. Pricing au compute + stockage. Recommandé pour les structures 100+ personnes avec des besoins IA avancés.
Data Contract : Accord formel entre producteurs et consommateurs de données définissant le schéma, la qualité attendue et les SLA (Service Level Agreement).
dbt (Data Build Tool) : Outil de transformation de données en SQL avec tests automatisés et documentation intégrée. Devenu le standard du marché pour l'Analytics Engineering. Portable entre data warehouses.
Embedding : Représentation vectorielle (numérique) d'un texte ou d'une image. Permet la recherche sémantique : trouver des documents similaires en sens, pas juste en mots-clés. Essentiel pour les agents IA.
ETL/ELT :
ETL (Extract-Transform-Load) : Extraire les données, les transformer puis les charger dans le warehouse (ancien paradigme)
ELT (Extract-Load-Transform) : Extraire, charger puis transformer dans le warehouse (paradigme moderne, plus flexible)
Lakehouse : Architecture combinant data lake (coût faible, stockage brut) et data warehouse (performance SQL, requêtes rapides). Recommandé pour l'IA moderne.
Medallion (Bronze/Silver/Gold) : Pattern d'organisation des données en 3 couches :
Bronze : Données brutes telles quelles
Silver : Données nettoyées et dédupliquées
Gold : Données transformées prêtes pour les métiers (dashboards, IA)
Pinecone : Base de données vectorielle managée, optimisée pour stocker et rechercher des embeddings. Utilisée pour le RAG (Retrieval-Augmented Generation) dans les agents IA.
PII (Personal Identifiable Information) : Données personnelles soumises au RGPD (nom, prénom, email, téléphone, adresse IP, identifiant client, etc.). Doivent être protégées et tracées.
RAG (Retrieval-Augmented Generation) : Technique IA combinant recherche dans une base de connaissances + génération de texte par un LLM. Permet à un agent IA de répondre avec des informations précises et à jour.
RLS (Row-Level Security) : Sécurité au niveau ligne dans un data warehouse. Permet de filtrer automatiquement les données selon le rôle de l'utilisateur. Exemple : un commercial ne voit que ses propres clients.
Snowflake : Data warehouse cloud leader du marché. Pricing au compute + stockage séparément. Très scalable. Bon choix pour les structures de 80+ personnes.
Vector Database : Base de données spécialisée pour stocker et rechercher des embeddings (vecteurs numériques). Exemples : Pinecone, Weaviate, pgvector (extension PostgreSQL gratuite).
Blog
Contact
contact@iannis.fr
© 2025. All rights reserved.
SUIVEZ-MOI