
IA en entreprise: comment améliorer vraiment la qualité de vos résultats LLM ?
Découvrez les 4 niveaux d'amélioration des LLM : du prompt engineering au fine-tuning. Guide complet avec cas d'usage, coûts et méthodes de décision.
INTELLIGENCE ARTIFICIELLE
Iannis Iglesias
11/4/202530 min read


Comment améliorer la qualité de vos résultats LLM : le guide opérationnel pour 2026
Les entreprises investissent massivement dans les LLM : le marché mondial devrait atteindre 259 milliards de dollars d'ici 2030 selon Grand View Research. Pourtant, 74% des organisations peinent encore à générer de la valeur selon McKinsey (2024). Le principal frein ? La qualité des résultats.
La plupart des équipes utilisent les LLM de manière basique : prompts courts et génériques comme dans ChatGPT. Résultat : réponses imprécises, hallucinations fréquentes, manque de connaissances spécifiques à l'entreprise ou ton inadapté à la marque. Face à ces limites, beaucoup abandonnent ou se contentent de résultats médiocres.
L'opportunité manquée est pourtant énorme. Il existe un spectre complet de techniques pour améliorer drastiquement les performances des LLM : du prompt engineering avancé (que peu maîtrisent vraiment) au fine-tuning (dont la majorité n'a jamais entendu parler) en passant par le RAG et autres approches de pointe.
Cet article cartographie l'ensemble de ces méthodes par ordre de complexité croissante. Pour chacune : cas d'usage concrets, coûts réels, délais de mise en œuvre et critères de décision. L'objectif est pragmatique et orienté ROI, pensé pour les startups et scale-ups qui veulent passer de la promesse à la performance.
Comprendre le spectre des techniques d'amélioration
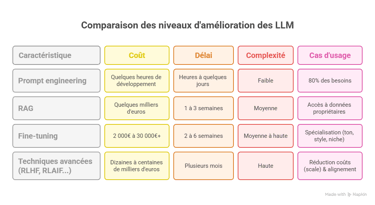
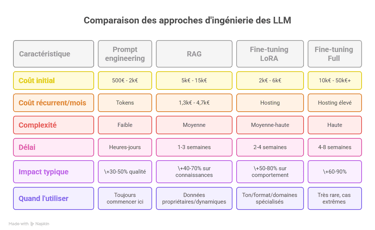
Les 4 niveaux d'amélioration des LLM
L'amélioration des performances d'un LLM n'est pas binaire. Il existe quatre niveaux de sophistication technique, chacun répondant à des problèmes spécifiques avec des investissements croissants.
Niveau 1 : Prompt engineering
Le prompt engineering consiste à optimiser la manière dont vous formulez vos instructions au modèle. C'est la première ligne d'amélioration et souvent la plus sous-exploitée.
Coût : Quelques heures de développement
Délai : Heures à quelques jours
Complexité : Faible (aucune infrastructure technique requise)
Cas d'usage : 80% des besoins peuvent être résolus ici
Niveau 2 : RAG (Retrieval-Augmented Generation)
Le RAG connecte votre LLM à des bases de connaissances externes. Le modèle récupère les informations pertinentes en temps réel avant de générer sa réponse.
Coût : Quelques milliers d'euros (développement + infrastructure)
Délai : 1 à 3 semaines de mise en œuvre
Complexité : Moyenne (architecture technique à construire)
Cas d'usage : Accès à données propriétaires ou fréquemment mises à jour
Niveau 3 : Fine-tuning
Le fine-tuning ré-entraîne un modèle pré-existant sur vos données spécifiques pour adapter son comportement, son ton ou ses capacités à votre contexte métier.
Coût : 2 000€ à 30 000€+ selon l'approche
Délai : 2 à 6 semaines
Complexité : Moyenne à haute (compétences ML requises)
Cas d'usage : Comportement très spécifique, volumes élevés, domaines de niche
Niveau 4 : Techniques avancées
Cette catégorie regroupe les approches de pointe : distillation de modèles, RLHF/RLAIF, continued pre-training.
Coût : Dizaines à centaines de milliers d'euros
Délai : Plusieurs mois
Complexité : Haute (équipe ML dédiée)
Cas d'usage : Cas spécifiques à très forte valeur ajoutée
Les trois axes d'amélioration
Chaque technique agit sur des dimensions différentes de la performance. Comprendre ces axes permet de choisir la bonne approche.
Axe 1 : Comportement du modèle
Cet axe concerne la manière dont le modèle s'exprime : ton, style, structure des réponses, format de sortie.
Problèmes résolus :
Réponses trop verbales ou trop courtes
Ton inadapté à votre marque
Formats de sortie incohérents (JSON mal formé, structures non respectées)
Manque de professionnalisme ou au contraire trop formel
Solutions :
Prompt engineering : Pour 90% des besoins comportementaux
Fine-tuning : Quand le comportement doit être absolument stable sur des millions de requêtes
Axe 2 : Connaissances du modèle
Cet axe traite de ce que le modèle sait : accès aux données, actualité des informations, connaissances propriétaires.
Problèmes résolus :
Le modèle ne connaît pas vos produits, vos processus internes, votre documentation
Les informations sont obsolètes (la plupart des LLM ont une date limite de connaissances)
Hallucinations sur des sujets où le modèle manque de données fiables
Solutions :
RAG : Solution par défaut pour 90% des besoins en connaissances
Prompt engineering : Quand le contexte peut être inclus directement dans le prompt
Fine-tuning : Uniquement pour domaines spécialisés sous-représentés dans les données de pré-entraînement
Axe 3 : Performance et coûts
Cet axe concerne l'efficacité opérationnelle : vitesse de réponse, coûts d'inférence, fiabilité.
Problèmes résolus :
Coûts d'API trop élevés à scale (plusieurs milliers d'euros mensuels)
Latence inacceptable pour l'expérience utilisateur
Taux d'erreur trop important en production
Solutions :
Optimisations simples : Caching, compression de prompts, batch processing
Switch de modèle : Migrer vers un modèle plus petit et plus rapide
Fine-tuning (affinage) : Continuer l'entraînement d'un modèle sur des données spécifiques pour améliorer sa précision ou sa fiabilité sur une tâche
Pourquoi cette progression est cruciale
Le principe de complexité minimale doit guider toute démarche d'amélioration. Résoudre un problème avec l'approche la plus simple possible présente trois avantages majeurs.
Avantage 1 : Limiter la multiplication exponentielle des coûts
Chaque niveau supérieur multiplie les coûts par 5 à 10x :
Prompt engineering : 500€ à 2 000€ (quelques jours dev)
RAG : 3 000€ à 10 000€ (2-3 semaines dev + infra)
Fine-tuning LoRA : 5 000€ à 15 000€ (4-6 semaines + compute)
Fine-tuning complet : 20 000€ à 100 000€+
Avantage 2 : Limiter les délais incompressibles
Le time-to-value augmente dramatiquement :
Prompt engineering : résultats en quelques heures
RAG : premières améliorations en 1-2 semaines
Fine-tuning : minimum 3-4 semaines avant premier résultat exploitable
Pour une startup en mode croissance rapide, ces semaines peuvent faire la différence entre capter une opportunité ou la manquer.
Avantage 3 : Réversibilité et flexibilité
Les solutions simples sont faciles à modifier :
Un prompt se change en 5 minutes
Une architecture RAG se réoriente en quelques jours
Un modèle fine-tuné nécessite de tout recommencer (plusieurs semaines + coûts)
Les données parlent
Selon le Stanford AI Index 2024, 82% des cas d'usage LLM en entreprise sont résolus par les niveaux 1 et 2 (prompt engineering + RAG). Seulement 18% nécessitent effectivement du fine-tuning ou des techniques plus avancées. Une startup qui fine-tune sans avoir exploré les alternatives perd en moyenne 2 à 3 semaines et 8 000€ à 15 000€ selon les données de Modal (plateforme d'infrastructure ML).
Le message est clair : explorer méthodiquement chaque niveau avant de passer au suivant n'est pas un luxe, c'est une nécessité stratégique.

Niveau 1 — Le prompt engineering (la fondation sous-exploitée)
Pourquoi la plupart sous-exploitent le prompt engineering
Le prompt engineering souffre d'un paradoxe : tout le monde pense le maîtriser alors que très peu l'exploitent réellement.
Le constat terrain
La majorité des équipes utilisent les LLM avec la même approche que ChatGPT : prompts courts, instructions vagues, attentes génériques. Voici un exemple typique d'un prompt sous-optimisé :
"Résume ce document pour notre équipe commerciale."
Résultat : une réponse générique, trop longue ou trop courte, sans les points clés pour l'action commerciale, dans un ton inadapté. Face à ce résultat décevant, la conclusion hâtive est souvent : le modèle n'est pas assez bon, il faut en changer ou investir dans du fine-tuning.
En réalité, les modèles récents (GPT-5, Claude Sonnet 4.5, Gemini 2.5...) sont remarquablement capables si correctement sollicités.
Les trois capacités sous-exploitées :
Capacité 1 : Context windows massifs
Les modèles actuels supportent des context windows considérables :
GPT-5 : 400 000 tokens
Claude Sonnet 4.5 : 200 000 tokens
Gemini 2.5 : jusqu'à 1 millions de tokens et prochainement 2 millions
Pour mettre ces chiffres en perspective : 200 000 tokens représentent environ 150 000 mots, soit l'équivalent de 2 à 3 romans. Avec Gemini 2.5 Pro, vous pouvez inclure l'équivalent de 20 romans dans un seul prompt.
Vous pouvez donc inclure : documentation complète, historiques de conversations, dizaines d'exemples, contexte métier exhaustif. La plupart des équipes n'utilisent que 5 à 10% de cette capacité disponible. Néanmoins nous le verrons plus tard ce n'est pas forcément très efficace de le faire de cette façon!
Capacité 2 : Compréhension d'instructions complexes
Les LLM 2025 peuvent suivre des consignes en plusieurs étapes, avec conditions, exceptions et formats précis. Ils comprennent les nuances : "Sois formel sans être rigide", "Technique sans être jargonnant". Cette flexibilité reste largement inexploitée.
Capacité 3 : Raisonnement avancé sur demande
Les modèles peuvent décomposer un problème, explorer plusieurs pistes, s'auto-corriger. Encore faut-il leur demander explicitement via les bonnes techniques ( nous en couvrons certaines à connaitre absolument ci-dessous).
L'opportunité économique
Le marché du prompt engineering devrait passer de 280 millions de dollars en 2024 à 2,5 milliards de dollars en 2032 selon les projections d'Artificial Intelligence Market. Cette croissance n'est pas un hasard : les entreprises réalisent qu'investir dans l'optimisation de leurs prompts génère un ROI immédiat sans infrastructure lourde.
Les techniques de prompt engineering qui fonctionnent
Voici les approches validées par la recherche et l'usage en production, par ordre de sophistication croissante.
Zero-shot prompting : la clarté absolue
Le zero-shot consiste à donner des instructions précises sans exemples. La clé : passer du vague au spécifique.
Avant (sous-optimisé) :
Résume ce texte
Après (optimisé) :
Produis un résumé en 3 points de maximum 20 mots chacun. Focus exclusif sur les décisions actionnables pour notre équipe commerciale. Format : tirets. Ton : direct et factuel, pas de langue de bois. Structure de chaque point : [Action] - [Bénéfice client] - [Timeline]
Impact mesuré : Une étude Google DeepMind (2024) montre une amélioration de 43% de la pertinence des réponses simplement en structurant les instructions.
Few-shot prompting : montrer plutôt qu'expliquer
Inclure 2 à 5 exemples du format attendu permet au modèle de comprendre par analogie. Exemple pour extraction de données structurées :
Extrais les informations suivantes au format JSON.
Exemple 1:
Texte: "Jean Dupont, 45 rue de la Paix, Paris, tel: 0612345678"
Output: {"nom": "Dupont", "prenom": "Jean", "adresse": "45 rue de la Paix, Paris", "tel": "0612345678"}
Exemple 2:
Texte: "Marie Martin habite 12 avenue Victor Hugo à Lyon, joignable au 0687654321"
Output: {"nom": "Martin", "prenom": "Marie", "adresse": "12 avenue Victor Hugo, Lyon", "tel": "0687654321"}
Maintenant, traite ce texte: [Votre texte ici]
Cette approche est particulièrement efficace pour les formats structurés : JSON, tableaux, classifications. Elle évite 90% des erreurs de parsing selon les benchmarks Anthropic.
Structured Prompting: structurer les contraintes
Cette technique consiste à définir très précisément le rôle, les contraintes et le format attendu. Exemple:
# Rôle
Tu es un analyste financier senior spécialisé en valorisation de startups tech B2B SaaS avec 10+ ans d'expérience.
# Contraintes
- Tu dois TOUJOURS citer tes sources ou indiquer "hypothèse" quand tu supposes
- En cas d'incertitude, dis-le explicitement plutôt que d'inventer
- Évite le jargon sans définition
- Maximum 300 mots par réponse
# Format de sortie
Réponds toujours en suivant cette structure :
1. Synthèse exécutive (50 mots max)
2. Analyse détaillée (200 mots max)
3. Recommandations actionnables (3 bullets, 15 mots max chacun)
4. Sources et hypothèses
Maintenant, analyse cette startup : [Données]
Le structured prompting transforme un modèle générique en expert spécialisé. Réduction des hallucinations : 60 à 70% selon Anthropic.
Chain-of-Thought (CoT) : déclencher le raisonnement
La technique CoT demande explicitement au modèle d'expliciter son raisonnement étape par étape avant de conclure.
Prompt standard : Quelle est la meilleure stratégie de pricing pour ce produit SaaS ?
Prompt avec CoT :
Analyse la stratégie de pricing optimale pour ce produit SaaS. Procède étape par étape :
1. Identifie le segment de marché et les comparables
2. Analyse la proposition de valeur unique
3. Évalue la sensibilité prix de la cible
4. Propose 3 modèles de pricing avec leurs avantages/inconvénients
5. Recommande le modèle optimal avec justification
Prends ton temps pour réfléchir à chaque étape.
Les recherches de l'Université de Stanford (Wei et al., 2024) démontrent une amélioration de 35 à 50% sur les tâches de raisonnement complexe : analyse financière, résolution de problèmes logiques, planification stratégique..
Tree of Thought (ToT) : explorer plusieurs chemins
Extension du CoT, le Tree of Thought demande au modèle d'explorer plusieurs raisonnements en parallèle avant de converger.
Pour résoudre ce problème de [X], explore 3 approches différentes :
Approche A : [Angle 1]
- Raisonnement
- Avantages
- Limites
Approche B : [Angle 2]
- Raisonnement
- Avantages
- Limites
Approche C : [Angle 3]
- Raisonnement
- Avantages
- Limites
Ensuite, compare ces approches et recommande la meilleure avec justification.
Cette technique brille sur les problèmes ouverts avec plusieurs solutions viables : stratégie produit, architecture technique, plans d'action complexes. Amélioration mesurée : +25 à 40% sur la qualité décisionnelle selon Yao et al. (2024).
Reverse prompting : partir de la fin
Technique méconnue mais redoutablement efficace : donner au modèle le résultat souhaité et lui demander de reconstruire le chemin.
Voici le livrable final attendu :
[Insérer exemple du format parfait que vous voulez]
En te basant sur cet exemple, traite maintenant ces nouvelles données en respectant exactement la même structure, le même niveau de détail et le même ton.
Données à traiter : [Vos données]
Cette approche inverse la logique habituelle. Au lieu d'expliquer ce que vous voulez, vous montrez le résultat. Le taux de réussite du premier coup passe de 60-70% à 85-95% selon les retours de Dust.tt sur leurs implémentations clients.
Quand le prompt engineering atteint ses limites ?
Le prompt engineering est puissant pour des cas simples mais reste fondamentalement fragile. Avant de lister les signaux indiquant qu'il faut passer au niveau supérieur, comprenons ses limites structurelles.
Limite 1 : Formats variables et imprévisibilité
Même avec des prompts très détaillés, les LLM peuvent varier dans leurs sorties du fait de leur nature probabiliste. Sur 100 exécutions du même prompt :
5 à 15% peuvent avoir un format légèrement différent
Les hallucinations restent possibles (le modèle invente des informations)
La cohérence n'est jamais garantie à 100%
Pour des systèmes critiques nécessitant une fiabilité absolue, cette variabilité est inacceptable.
Limite 2 : Hallucinations avec contextes très longs
Paradoxalement, plus vous injectez de contexte, plus vous risquez des hallucinations. Avec des context windows de 200K à 2M tokens :
Le modèle peut "se perdre" dans la masse d'informations
Difficulté à identifier les informations réellement clés
Augmentation du taux d'erreur sur certaines tâches complexes (phénomène "lost in the middle" documenté par Liu et al., 2024)
Limite 3 : Maintenance et évolution
Les prompts sont du code fragile :
Chaque modification peut avoir des effets de bord imprévisibles
Pas de versioning robuste comme pour du code classique
Difficile à tester systématiquement sur tous les cas d'usage
Limite 4 : Coûts cachés sur gros volumes
À partir de plusieurs milliers de requêtes mensuelles, les longs prompts coûtent cher :
un prompt structuré de 4 000 tokens (incluant du contexte et des exemples) pour une application générant 1 million de requêtes mensuelles.
Calcul : 4 000 tokens/prompt × 1 000 000 requêtes = 4 milliards de tokens.
Coût (GPT-5) : À 1,25$ par million de tokens en entrée, cela représente environ 5 000€ par mois en input tokens uniquement. Les output tokens à 10$/million ajoutent 10 000€ supplémentaires pour 1 milliard de tokens générés, soit 15 000€ total.
Note : GPT-5 a réduit de 50% le coût des inputs vs GPT-4o (2,50$/M), mais le vrai coût vient souvent des outputs surtout avec le reasoning qui génère des "thinking tokens" invisibles comptés comme output. Ce calcul montre l'importance d'optimiser non seulement les prompts mais aussi la longueur des réponses générées.
Le prompt engineering reste la première étape obligatoire mais ne doit pas être vu comme la solution finale pour des use cases critiques ou à très gros volume.
Quatre signaux indiquent qu'il faut passer au niveau supérieur.
Signal 1 : Itérations sans fin
Vous avez testé 15, 20, 30 variations de prompts sans obtenir de résultats satisfaisants. Le problème n'est probablement pas la formulation mais les connaissances manquantes dans le modèle ou un besoin de comportement structurel différent. Règle empirique : Au-delà de 10 à 15 itérations sur le même prompt, le problème est ailleurs.
Signal 2 : Context window insuffisant
Même avec des context windows de 200K à 2M tokens, certains cas d'usage nécessitent plus : analyse de corpus massifs de documents, historiques clients sur plusieurs années, bases de connaissances géantes dépassant 10 millions de mots. Si vous devez constamment décider quel contexte inclure ou exclure, vous avez besoin de RAG.
Signal 3 : Données post-cutoff ou propriétaires
Le modèle n'a accès qu'aux données présentes lors de son entraînement. Si vous avez besoin :
D'informations postérieures au knowledge cutoff du modèle
De documentation interne, processus, produits spécifiques à votre entreprise
De données temps réel (cours de bourse, actualités, événements)
Alors le prompt engineering ne peut rien pour vous. La solution est le RAG (niveau 2).
Signal 4 : Comportement critique répété régulièrement
Si vous avez un use case en production avec des milliers de requêtes mensuelles et que chaque variation de comportement coûte cher (hallucination, ton inadapté, erreur de format), le fine-tuning peut se justifier pour stabiliser et optimiser.
Seuil indicatif : Au-delà de 50K à 100K de requêtes mensuelles, calculez le ROI du fine-tuning.
Niveau 2 - RAG (quand les connaissances manquent)
Qu'est-ce que le RAG et pourquoi c'est devenu le standard entreprise ?
Le Retrieval-Augmented Generation (RAG) connecte votre LLM à vos bases de connaissances pour récupérer les informations pertinentes en temps réel avant de générer une réponse. La métaphore : donner au modèle accès à une bibliothèque qu'il peut consulter avant de répondre, plutôt que de tout garder en mémoire.
L'explosion du marché
Le marché RAG pèse 1,94 milliards de dollars en 2025 et devrait atteindre 9,86 milliards de dollars en 2030 (Croissance annuel de 38,4% selon MarketsandMarkets). Plus révélateur encore : 71% des early adopters de GenAI ont déjà implémenté un projet RAG selon le rapport Snowflake 2025. Ce n'est plus une technologie émergente, c'est le standard de facto pour toute application IA en entreprise.
Le problème résolu
Les LLM ont deux limites structurelles :
Knowledge cutoff : Leur connaissance s'arrête à une date (janvier 2025 pour les plus récents à l'heure d'écrire cet article en Novembre 2025)
Pas d'accès aux données propriétaires : Ils ignorent tout de votre documentation, vos processus, vos produits
Ré-entraîner un modèle à chaque mise à jour de données est impossible : coûts prohibitifs, délais de plusieurs semaines, complexité technique. RAG contourne élégamment ce problème.
L'architecture RAG en 4 étapes
Étape 1 : Indexation (préparation)
Vos documents (PDF, Word, Notion, Slack, Drive...) sont découpés en passages (chunks) de 200 à 1 000 tokens. Chaque passage est transformé en vecteur numérique (embedding) via un modèle spécialisé. Ces vecteurs sont stockés dans une vector database (Pinecone, Qdrant, Weaviate, Chroma).
Étape 2 : Retrieval (récupération)
L'utilisateur pose une question. Le système cherche les passages les plus pertinents via semantic search (recherche par similarité de sens, pas par mots-clés). Les 3 à 10 passages les plus pertinents sont récupérés.
Étape 3 : Augmentation (enrichissement)
Les passages récupérés sont ajoutés au contexte du prompt envoyé au LLM. Le modèle reçoit donc : question + contexte pertinent tiré de vos données.
Étape 4 : Génération (réponse)
Le LLM génère sa réponse en s'appuyant sur les documents fournis. Il peut citer ses sources (traçabilité).
Les avancées 2025 : GraphRAG
GraphRAG combine recherche vectorielle et knowledge graphs pour apporter contexte et logique. Résultat : jusqu'à 99% de précision selon les implémentations de pointe (contre 60-75% pour RAG basique). L'approche structure les relations entre concepts au lieu de se limiter à la similarité sémantique.
Le cas Dust.tt : Quand le RAG connecte Slack, Google Drive et Notion
Dust est une plateforme française d'agents IA qui illustre parfaitement la puissance du RAG en tant que produit pour l'entreprise.
Le problème adressé
Les équipes passent en moyenne 2,5 heures par jour à chercher de l'information dispersée entre Slack, Google Drive, Notion, Confluence, GitHub et emails. Cette friction ralentit la prise de décision et génère frustration et perte de productivité.
La solution RAG
Dust connecte tous ces outils via +20 connecteurs natifs et centralise la connaissance d'entreprise :
Documentation produit dans Notion
Conversations clients dans Slack
Contrats et présentations dans Google Drive
Code et specs techniques dans GitHub
Tickets et processus dans outils métiers
L'architecture RAG utilise Qdrant comme vector database et indexe l'intégralité des sources connectées. Les équipes peuvent ensuite interroger cette base unifiée en langage naturel.
Les résultats
+90% d'adoption dans les déploiements clients (taux d'utilisateurs actifs mensuels)
Réduction de 70% du temps de recherche d'information
ROI moyen +1900% selon les données internes
Cas d'usage spécifiques
Support client : Les agents répondent aux tickets en s'appuyant sur la documentation à jour, sans copier-coller manuel
Onboarding : Les nouveaux employés accèdent instantanément à toute la connaissance entreprise via chatbot
Sales : Génération automatique de réponses aux appels d'offres en récupérant les contenus existants
Architecture technique
L'architecture de Dust n'est pas seulement technique, elle est conçue pour résoudre les freins habituels à l'adoption en entreprise :
Sécurité et Permissions (Security & Permissions) : Le système intègre des permissions granulaires (via des "Spaces") pour segmenter les accès par rôle. Concrètement : l'équipe RH n'accède pas aux données de l'équipe R&D, et inversement.
Conformité (Compliance) : La plateforme est certifiée (SOC2 Type II, GDPR compliant) et propose l'hébergement en UE (EU Hosting). C'est un point clé pour être validé par les équipes juridiques et de sécurité.
Approche "No-Code" : L'implémentation est rapide. Les équipes métier (ops, marketing, sales) peuvent configurer et utiliser l'outil sans dépendre d'un cycle de développement long.
Flexibilité (Model-Agnostic) : Le système n'est pas "enfermé" (locked-in) avec un seul fournisseur. Il permet de choisir le LLM le plus adapté (GPT-4, Claude, Mistral, Gemini) pour optimiser l'équilibre entre coût et performance selon le cas d'usage.
RAG vs Fine-tuning : quand utiliser quoi
La confusion est fréquente. RAG et fine-tuning ne sont pas opposés, ils résolvent des problèmes différents.
Utilisez un RAG pour :
✅ Données dynamiques
Documentation mise à jour régulièrement
Catalogues produits, pricing, stock
Veille réglementaire ou juridique
Actualités et tendances sectorielles
✅ Grandes bases de connaissances
Millions de documents
Historiques clients sur plusieurs années
Bases juridiques, médicales, techniques
✅ Besoin de traçabilité
Citer les sources (compliance)
Vérifier les informations
Audit trail obligatoire
✅ Réduction des hallucinations
Réponses ancrées dans des faits vérifiables
Ground truth disponible
Utilisez le fine-tuning pour :
✅ Comportement et ton
Style de communication spécifique
Voix de marque unique
Formats de sortie structurés répétitifs
✅ Domaines sous-représentés
Langues rares
Jargon ultra-technique
Terminologie propriétaire
✅ Optimisation coûts à très gros volume
Distiller GPT-4 vers Llama 7B
Réduire latence et coûts d'inférence
ROI positif au-delà de 10M requêtes/mois
L'approche hybride (recommandée)
Les entreprises les plus avancées combinent RAG et fine-tuning :
RAG pour les connaissances (produits, documentation, processus)
Fine-tuning pour le ton de marque et les formats structurés
Résultat : Réponses avec le bon ton ET les bonnes informations.
Exemple : Malt (plateforme de freelances française) utilise un modèle fine-tuné pour respecter son tone of voice et ses guidelines éditoriales, couplé à RAG pour accéder aux profils freelances, aux projets et à la documentation métier. Retrouve la vidéo complète ici: Comment Malt a déployé un Assistant IA (Dust, Gemini…) pour booster l'efficacité en interne
Les coûts réels du RAG
Décomposition pour une implémentation startup/scale-up (50-200 employés) :
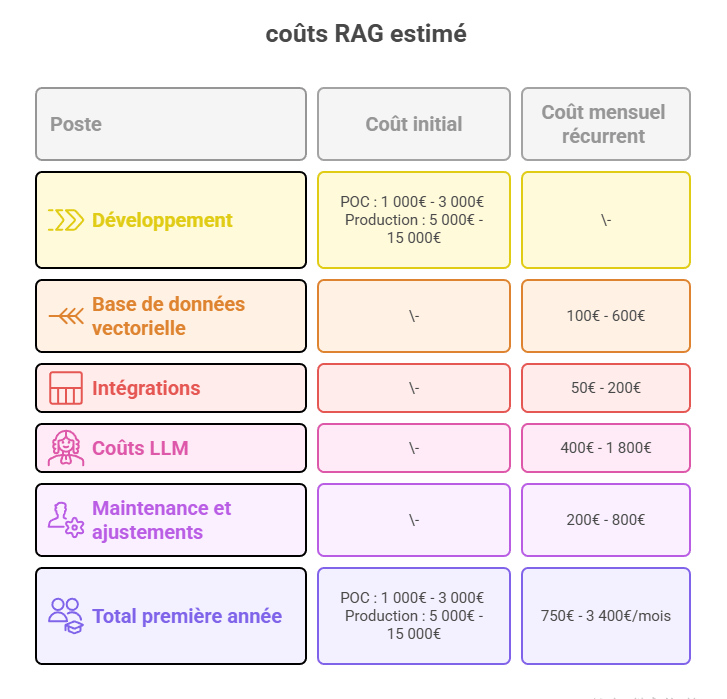
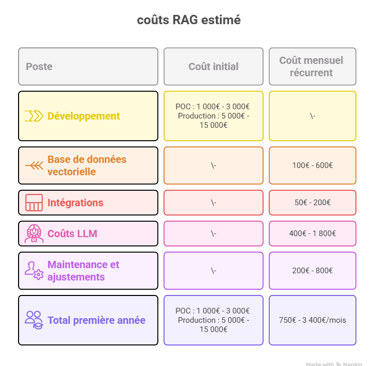
Note : Ces coûts correspondent à un usage production établi. Une startup peut démarrer bien moins cher :
Phase exploration/MVP : 50€-200€/mois (free tiers + petits volumes)
Croissance initiale : 200€-800€/mois
Production scale-up : 750€-3 400€/mois
Breakeven typique : 2 à 4 mois selon le gain de productivité mesuré.
Comparaison avec les alternatives :
Prompt engineering seul : Gratuit mais limité aux connaissances du modèle
Fine-tuning : 5 000€ - 30 000€ initial sans résoudre le problème de connaissances
RAG : Compromis optimal pour 90% des besoins entreprise
Les pièges à éviter
Piège 1 : Chunking inadapté
Des chunks trop courts perdent le contexte, trop longs diluent la pertinence. La taille optimale dépend du contenu : 200-400 tokens pour FAQ, 500-1 000 tokens pour documentation technique.
Piège 2 : Retrieval de mauvaise qualité
Si les passages récupérés ne sont pas pertinents, le modèle génère des réponses à côté. Investir dans le tuning du retrieval (seuils de similarité, re-ranking) est crucial.
Piège 3 : Fraîcheur des données négligée
Un RAG qui indexe des documents obsolètes est pire qu'inutile : il donne des informations fausses avec confiance. Mettre en place une sync automatique (quotidienne ou hebdomadaire selon le use case).
Piège 4 : Permissions et sécurité mal gérées
RAG a accès à vos données sensibles. Sans permissions granulaires, risque de fuite d'informations confidentielles. Implémenter un système de filtrage par rôle dès le départ.
Quand le RAG ne suffit pas
Deux signaux indiquent qu'il faut passer au fine-tuning en complément :
Signal 1 : Le ton n'est jamais bon
RAG récupère les bonnes informations mais les formulations sont génériques ou inadaptées à votre marque. Le modèle n'a pas intégré votre voix éditoriale.
Signal 2 : Formats de sortie instables
Vous avez besoin de JSON structuré complexe répété des millions de fois. RAG seul ne garantit pas la stabilité du format à 100%.
Dans ces cas : combinez RAG (pour les connaissances) + fine-tuning (pour le comportement).
Niveau 3 - Le fine-tuning (ajuster le comportement du modèle)
Ce qu'est vraiment le fine-tuning
Le fine-tuning (ou ajustement fin en français) consiste à poursuivre l'entraînement d'un modèle déjà performant sur vos données spécifiques pour adapter son comportement. Au lieu d'entraîner un modèle from scratch (coût : plusieurs millions d'euros, des mois de travail), vous partez d'un modèle comme Llama, Mistral ou Gemma et vous l'affinez sur quelques milliers d'exemples.
La métaphore : Engager un expert généraliste brillant et lui offrir une formation intensive dans votre domaine. Il conserve toutes ses capacités générales (grammaire, raisonnement) tout en acquérant une expertise pointue dans votre terminologie et vos standards.
Ce que le fine-tuning change vraiment
Le fine-tuning modifie les poids internes du modèle (les milliards de paramètres qui définissent son comportement). Résultat : le modèle intègre profondément vos besoins au lieu de simplement suivre des instructions dans un prompt.
Différence concrète :
Prompt engineering : "Réponds en style formel mais accessible"
→ Le modèle fait de son mieux mais peut dévierFine-tuning : Le modèle a vu 10 000 exemples de ce style
→ Le comportement devient naturel et stable
Les vrais cas d'usage du fine-tuning
Le fine-tuning n'est pas la solution miracle. Voici quand il fait vraiment sens :
✅ Cas 1 : Ton et voix de marque impossibles à capturer en prompt
Vous avez un style rédactionnel unique, un niveau de formalisme précis, une manière spécifique de structurer vos réponses. Après 20 itérations de prompts, le résultat n'est toujours pas satisfaisant.
Exemple : Malt (plateforme de freelances française) a fine-tuné un modèle pour respecter son ton de voix et ses guidelines éditoriales sur tous les contenus générés.
✅ Cas 2 : Formats de sortie structurés critiques
Vous générez du JSON, XML ou CSV avec des structures complexes. Chaque erreur de format coûte cher en post-traitement. Le fine-tuning réduit les erreurs de parsing de 60 à 90%.
✅ Cas 3 : Domaines sous-représentés
Votre secteur utilise un jargon ultra-technique absent des données d'entraînement des modèles généralistes : nomenclature chimique, termes juridiques très spécialisés, langues régionales.
✅ Cas 4 : Réduction de coûts sur de gros volumes
Vous faites 1+ millions de requêtes mensuelles avec GPT-4. Distiller ses capacités dans un modèle Llama 7B fine-tuné peut diviser vos coûts par 20x.
Cas réel : Mirakl, licorne française des marketplaces, dépensait 500 000€/mois avec GPT-4 à l'échelle. Ils ont fine-tuné Llama pour certains use cases et réduit drastiquement leurs coûts tout en maintenant la qualité. Outil utilisé : Galileo pour optimiser les données d'entraînement et minimiser les hallucinations.
✅ Cas 5 : Tâches NLP traditionnelles
Classification de textes, extraction d'entités nommées, analyse de sentiment. Le fine-tuning peut encore battre les approches zero-shot.
❌ Quand NE PAS fine-tuner
Phase MVP/exploration : Trop d'incertitude sur le use case final
Domaines mainstream bien couverts : Le prompt engineering suffit
Données changeant fréquemment : RAG est plus adapté
Petit dataset (<100-200 exemples) : Risque majeur de surapprentissage
Budget limité (<5 000€) : Explorez d'abord toutes les alternatives
Exemple concret : Malt et le fine-tuning pour la voix de marque
Contexte Malt, plateforme française de freelances (500K+ freelances, +1M missions réalisées), avait besoin de générer automatiquement des contenus à grande échelle : descriptions de profils, réponses aux candidatures, emails de suivi, contenus marketing.
Le problème initial Avec GPT-4 et des prompts avancés :
- ✅ Contenu techniquement correct
- ❌ Ton générique, manque de personnalité
- ❌ Variabilité dans le style selon les prompts
- ❌ Guidelines éditoriales non respectées systématiquement
- ❌ Coût : ~12 000€/mois pour 3M de tokens output mensuels
La solution : Fine-tuning hybride
Phase 1 - Préparation données (3 semaines)
- Extraction de 2 500 contenus "parfaits" validés par l'équipe éditoriale
- Annotation du tone of voice : accessible, direct, bienveillant
- Formatage en paires instruction/réponse
- Coût : ~3 500€ (temps équipe + validation)
Phase 2 - Fine-tuning (2 semaines)
- Modèle : Mistral 7B (open-source, conformité RGPD)
- Technique : LoRA pour efficacité
- Infrastructure : Modal (cloud managé)
- 4 itérations pour optimiser hyperparamètres
- Coût : ~2 800€
Phase 3 - Architecture hybride déployée - RAG pour les données métier (profils, missions, processus)
- Modèle fine-tuné pour le ton et les formats de sortie
- Self-hosted sur infrastructure européenne
Résultats mesurés (6 mois post-déploiement)
Qualité :
- Respect du tone of voice : 92% (vs 65% avec prompts seuls)
- Validation éditoriale 1er coup : 85% (vs 50%)
- Satisfaction équipes internes : +40%
Coûts :
- Inférence : ~1 200€/mois (self-hosted)
- Économie vs GPT-4 : 10 800€/mois
- ROI : Investissement initial remboursé en 2 mois
Scalabilité :
- Traitement : 5M tokens/mois (capacité 20M)
- Latence : 200ms vs 800ms avec GPT-4
- Disponibilité : 99,7%
Leçons clés
1. L'approche hybride RAG + fine-tuning est optimale pour la plupart des use cases
2. La qualité des données d'entraînement (2 500 exemples parfaits > 10 000 médiocres)
3. Le ROI est rapide si volume suffisant (>1M tokens/mois)
4. L'ownership du modèle permet des itérations rapides sans dépendance externe
Source : [Comment Malt a déployé un Assistant IA]
Les approches de fine-tuning : du plus cher au plus accessible
Approche 1 : Full fine-tuning (ajustement complet)
Tous les paramètres du modèle sont ré-entraînés. Performance maximale mais coûts prohibitifs.
Coût : 10 000€ à 50 000€+
Durée : Plusieurs jours à plusieurs semaines
Hardware : GPUs haut de gamme (A100, H100)
Cas d'usage : Extrêmement rare, réservé aux modèles propriétaires stratégiques
Approche 2 : LoRA (Low-Rank Adaptation) — Le standard 2025
Au lieu de modifier tous les paramètres, LoRA ajoute de petites matrices d'adaptation dans chaque couche du modèle. Ces matrices capturent les spécificités de votre tâche pendant que 99% du modèle reste gelé.
L'analogie : Au lieu de refaire toute la plomberie d'une maison, vous ajoutez des adaptateurs sur les robinets existants.
Avantages :
Coût divisé par 5 à 10x vs full fine-tuning
Performances : 90-95% de la qualité du full fine-tuning
Rapidité : Quelques heures à quelques jours
Stockage : Les adaptateurs LoRA pèsent quelques centaines de Mo au lieu de dizaines de Go
Chiffres concrets :
Full fine-tuning Mistral 7B : 10 000€ - 12 000€
LoRA sur Mistral 7B : 1 500€ - 3 000€
Qualité équivalente
OpenAI estime que LoRA a réduit de 70% leurs coûts internes de fine-tuning.
Approche 3 : QLoRA (Quantized LoRA) — L'ultra-économique
QLoRA combine LoRA avec une compression du modèle (quantification 4-bit). Le modèle occupe 4x moins de mémoire.
Avantages :
Fonctionne sur GPU grand public (RTX 3090, 4090)
Coût : 500€ - 1 500€
Accessible aux startups sans infrastructure ML lourde
Trade-off : Légère dégradation qualité (acceptable pour beaucoup de cas)
Exemple concret : Fine-tuner un Llama 7B avec QLoRA nécessite ~18 GB de VRAM et prend ~3 heures sur une A100 pour 50 000 exemples d'entraînement.
Les modèles open-source à fine-tuner en 2025
Llama 4 (Meta) — Le leader polyvalent
Tailles : 8B, 70B, 405B paramètres
350M de téléchargements sur Hugging Face la première année
Licence Apache 2.0 (usage commercial libre)
Multilangue de qualité
Idéal pour : Usage général, volume élevé, besoin de flexibilité
Mistral & Mistral Large (Mistral AI 🇫🇷) — L'alternative européenne
Mistral : 7B paramètres, léger et performant
Mistral Large : 123B paramètres, 80+ langues
Open-source, souveraineté européenne
Très populaire en France/Europe
Idéal pour : Équilibre perf/coûts, multilangue, conformité RGPD
DeepSeek-V3 (DeepSeek 🇨🇳) — Le rapport qualité-prix
236B paramètres (architecture MoE : seulement 41B activés par token)
Coût de training : seulement 5,6M$ (vs 78M$ GPT-4)
Performances compétitives avec modèles fermés
Idéal pour : Gros modèle avec budget limité
Gemma 2 (Google) — L'efficient
27B offre perfs équivalentes à modèles 50B+
Très efficace en ressources
Bonne intégration écosystème Google
Idéal pour : Budgets limités, déploiement potentiel on-device
Critères de choix :
Taille vs budget compute disponible
Licence (Apache 2.0 ou MIT préférables)
Support multilingue si besoin
Communauté active (ressources, exemples, debugging)
Le processus opérationnel en 5 étapes
Étape 1 : Préparer le dataset (20-40% de l'effort total)
Volume nécessaire :
Minimum : 50-100 exemples pour LoRA simple
Recommandé : 500-2 000 exemples pour généralisation solide
Idéal : 5 000-10 000 exemples pour tâches complexes
Format : paires [instruction, réponse]
{
"instruction": "Analyse ce contrat et identifie les clauses de résiliation",
"input": "[texte du contrat]",
"output": "[analyse structurée attendue]"
}
La qualité prime sur la quantité : 500 exemples parfaits valent mieux que 5 000 exemples médiocres.
Pièges à éviter :
Dataset trop petit → surapprentissage (le modèle apprend par cœur)
Dataset trop homogène → manque de généralisation
Mauvaise qualité → le modèle apprend les erreurs
Étape 2 : Choisir l'infrastructure
Option 1 : Services managés
OpenAI Fine-tuning API : ~25$/million tokens training
Mistral API, Together AI, Replicate
Avantages : Simplicité, pas de gestion infra
Inconvénients : Moins de contrôle, lock-in
Option 2 : Cloud GPU
AWS, GCP, Azure : 0,50$ à 2$/heure selon GPU
Avantages : Flexibilité, scalabilité
Inconvénients : Coûts peuvent exploser, nécessite expertise
Option 3 : Plateformes spécialisées
Modal, Runpod, Lambda Labs
Avantages : Workflows optimisés, outils intégrés
Étape 3 : Lancer le fine-tuning
Frameworks recommandés :
Unsloth : Pour GPUs limités, optimisations mémoire (2-5x plus rapide)
Hugging Face PEFT : Standard industrie, documentation complète
LLaMA-Factory : Interface tout-en-un, supporte 100+ modèles
Durée typique :
Petit modèle 7B + LoRA : 2-6 heures
Gros modèle 70B + LoRA : 8-24 heures
Full fine-tuning : jours à semaines
Étape 4 : Évaluer rigoureusement
Métriques quantitatives :
Accuracy, F1 score selon la tâche
Comparer vs baseline (modèle non fine-tuné)
Évaluation qualitative :
Tester sur cas réels
Panel d'utilisateurs
A/B testing si possible
Vérifier le surapprentissage :
Performances sur training set vs validation set
Si gap important → surapprentissage
Étape 5 : Déployer et monitorer
Optimisations :
Quantification (4-bit, 8-bit) pour réduire coûts
Batching des requêtes
Caching des réponses fréquentes
Monitoring continu :
Qualité des outputs
Dérives éventuelles
Coûts réels d'inférence
Les coûts réels (tous compris)
Décomposition pour Mistral 7B + LoRA :
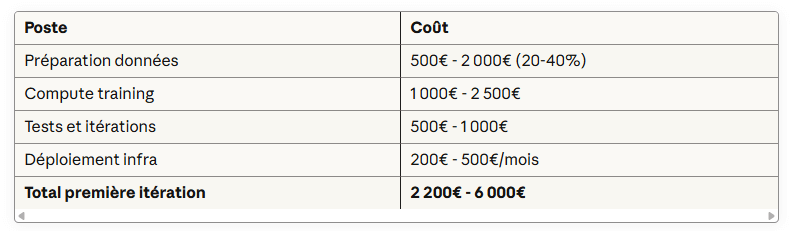
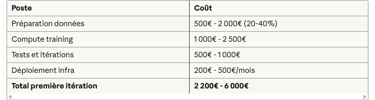
Comparaison coûts d'inférence :
Comparaison coûts d'inférence actualisés (2025) :
Modèles propriétaires (par million de tokens output) :
- GPT-5 : 10$
- Claude Sonnet 4.5 : 15$
- Gemini 2.5 Pro : 10$ (au-delà de 200K tokens input)
Modèles open-source fine-tunés (self-hosted) :
- Mistral 7B : ~0,40$ - 0,60$/million tokens
- Llama 3.2/4 8B : ~0,50$ - 0,70$/million tokens
- DeepSeek V3 : ~0,30$ - 0,50$/million tokens (architecture MoE efficiente)
ROI breakeven typique :
- 1-2 millions de requêtes mensuelles pour rentabiliser le fine-tuning
- Division des coûts par 15-25x vs modèles propriétaires premium
Cas d'usage documentés :
Mirakl (licorne française e-commerce, 177M$ ARR) :
- Fine-tuning de Llama, ChatGPT et Mistral 7B pour cas d'usage commerce
- 50 ingénieurs dédiés IA (sur 300 total)
- 80%+ des employés utilisent l'IA quotidiennement
- Investissements IA 2025 = somme des 3 années précédentes combinées
- Note : 500 000€/mois économisés en passant de GPT-4 à Llama fine-tuné sur certains use cases. Voir la vidéo
Benchmarks performance :
- Modèle 7B fine-tuné peut égaler modèles récents sur des tâches spécifiques
- Division coûts par 15-25x pour des use cases ciblés
- Performance maintenue avec 90-95% de la qualité de full fine-tuning (via LoRA)
Facteurs clés du ROI :
- Volume de requêtes (seuil rentabilité : 50K-100K/mois)
- Stabilité du use case (éviter re-training fréquent)
- Disponibilité de données de qualité pour le training
Les erreurs qui coûtent cher
❌ Erreur 1 : Fine-tuner trop tôt
Avant product-market fit → gaspillage 5 000€ -10 000€. Explorez d'abord prompt engineering + RAG.
❌ Erreur 2 : Dataset de mauvaise qualité
Garbage in, garbage out. Un dataset médiocre produit un modèle médiocre, peu importe la technique.
❌ Erreur 3 : Négliger l'évaluation
Déployer sans mesurer → découvrir les problèmes en production. Créez un golden set de test avant de commencer.
❌ Erreur 4 : Sous-estimer les coûts d'inférence
Fine-tuner un modèle 70B pour économiser vs GPT-4 mais les coûts d'hébergement mangent les économies. Calculez le ROI complet.
❌ Erreur 5 : Ne pas documenter
Impossible de reproduire ou d'itérer. Tracez : dataset, hyperparamètres, résultats, décisions.
Niveau 4 - Les techniques avancées (pour aller plus loin)
Cette section couvre rapidement les approches de pointe. La majorité des entreprises n'en auront jamais besoin.
Distillation de modèle (transférer les capacités)
Le principe : Entraîner un petit modèle (élève) à imiter un gros modèle (professeur).
Cas d'usage : Vous utilisez GPT-4 mais coûts trop élevés à scale. Distiller vers Llama 8B ou Mistral 7B.
Résultats : Division par 10-20x des coûts d'inférence. Vicuna-13B atteint 90% qualité ChatGPT selon évaluations GPT-4.
RLHF et RLAIF (aligner avec préférences)
RLHF (Reinforcement Learning from Human Feedback) : Entraîner le modèle via feedback humain sur qualité des réponses. Technique utilisée pour ChatGPT, Claude. Très coûteuse (annotateurs humains).
RLAIF (RL from AI Feedback) — Tendance 2025 : Remplacer humains par IA pour donner feedback. Scalabilité infinie, coûts divisés par 10-100x. Performances équivalentes à RLHF selon études récentes.
Cas d'usage : Aligner ton et sécurité du modèle, réduire outputs toxiques ou biaisés.
Continued pre-training (spécialisation profonde)
Le principe : Continuer le pré-entraînement du modèle sur corpus spécialisé AVANT fine-tuning.
Exemple : Nvidia ChipNeMo (Llama-2 continué sur données chip design).
Cas d'usage : Domaines ultra-spécialisés (médical, légal, scientifique), langues sous-représentées.
Coûts : Très élevés (proche du training from scratch).
Le framework de décision (comment choisir)
Le flowchart décisionnel
Question 1 : Le modèle de base (GPT-4, Claude, Mistral...) avec un prompt simple répond-il correctement ?
✅ Oui → Vous avez terminé. Ne compliquez pas.
❌ Non → Question 2
Question 2 : Avez-vous exploré toutes les techniques de prompt engineering ?
❌ Non → Investissez ici d'abord : few-shot, CoT, prompts structurés
✅ Oui (vraiment exploré, pas juste 2-3 tentatives) → Question 3
Question 3 : Le problème vient-il de connaissances manquantes ou obsolètes ?
✅ Oui (données propriétaires, info post-cutoff, documentation dynamique) → RAG
❌ Non → Question 4
Question 4 : Le problème est-il lié au comportement, ton ou format de sortie ?
✅ Oui + dataset de qualité (>100 exemples) + budget (2-6k€) → Fine-tuning (LoRA)
✅ Oui mais pas de dataset ou budget limité → Retour prompt engineering avancé
❌ Non → Question 5
Question 5 : Cherchez-vous à réduire coûts/latence sur gros volumes ?
✅ Oui (plusieurs millions de requêtes mensuelles) → Fine-tuning (distillation)
❌ Non → Vous avez atteint les limites actuelles des LLM pour votre use case

L'approche progressive (recommandée pour 90% des cas)
Semaine 1-2 : Prompt engineering
Tester zero-shot → few-shot → CoT
Structurer les prompts
Mesurer les améliorations
Objectif : Établir baseline de qualité
Semaine 3-4 : RAG si nécessaire
Identifier les manques de connaissances
PoC RAG sur subset de données
Mesurer amélioration vs baseline
Décision : ROI positif ? → Industrialiser
Mois 2-3 : Fine-tuning si justifié
Uniquement si prompt + RAG insuffisants
Préparer dataset de qualité
LoRA en priorité
Mesurer ROI précis
Décision : Gain > coût ?
Règle d'or : Ne jamais sauter d'étape. Chaque niveau doit être épuisé avant de passer au suivant.
Conclusion : L'amélioration des LLM est une question de méthode
Les 5 principes à retenir
1. La complexité minimale gagne toujours
80% des besoins résolus par prompt engineering + RAG. Fine-tuning uniquement quand ROI clair. Ne pas sur-ingénieuriser.
2. La progression méthodique est rentable
Prompt engineering (jours) → RAG (semaines) → Fine-tuning (mois). Chaque étape valide le besoin avant d'investir dans la suivante. Économie de 5 000€ à 20 000€ en évitant un fine-tuning prématuré.
3. Les données de qualité valent plus que la technique
Un dataset de 100 exemples excellents > 10 000 exemples médiocres. 20-40% de l'effort doit aller dans la préparation des données.
4. RAG et fine-tuning sont complémentaires
RAG pour les connaissances, fine-tuning pour le comportement. L'architecture hybride est souvent la meilleure solution.
5. L'écosystème 2025 rend tout plus accessible
LoRA divise les coûts par 5-10x. Outils démocratisés (Hugging Face, Unsloth). Modèles performants permettent fine-tuning sur budgets startups.
Le message final
Les LLM ne sont pas des boîtes noires magiques. Ce sont des outils puissants dont vous pouvez systématiquement améliorer la qualité en appliquant la bonne technique au bon moment.
La plupart des équipes sous-exploitent massivement les capacités actuelles simplement parce qu'elles ne connaissent pas le spectre complet des options. Commencez simple. Mesurez tout. Complexifiez uniquement quand les données le justifient.
Les entreprises qui réussissent leur adoption LLM en 2025 ne sont pas celles qui ont les plus gros budgets : ce sont celles qui ont la meilleure méthode.
Glossaire
API (Application Programming Interface) : Interface permettant à des applications de communiquer entre elles. Les LLM sont souvent accessibles via API.
Batch Processing : Traitement de multiples requêtes groupées ensemble pour optimiser les coûts et la performance.
BPE (Byte-Pair Encoding) : Méthode de tokenization qui divise le texte en sous-unités fréquentes.
Caching : Stockage temporaire de résultats pour réutilisation, réduisant coûts et latence.
Chain-of-Thought (CoT) : Technique de prompting demandant au modèle d'expliciter son raisonnement étape par étape.
Chunk / Chunking : Découpage de documents en passages plus petits (200-1000 tokens) pour l'indexation RAG.
Context Window : Quantité maximale de texte (en tokens) qu'un modèle peut traiter simultanément en entrée.
Continued Pre-training : Poursuivre le pré-entraînement d'un modèle sur un corpus spécialisé avant le fine-tuning.
Dataset : Ensemble de données utilisé pour entraîner ou évaluer un modèle.
Distillation : Technique transférant les capacités d'un grand modèle (professeur) vers un modèle plus petit (élève).
Embedding : Représentation vectorielle numérique d'un texte permettant les calculs de similarité sémantique.
E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) : Critères de qualité Google évaluant la crédibilité du contenu.
Few-Shot Prompting : Technique incluant 2-5 exemples dans le prompt pour guider le modèle par analogie.
Fine-Tuning : Ré-entraînement d'un modèle pré-existant sur des données spécifiques pour adapter son comportement.
Full Fine-Tuning : Fine-tuning modifiant tous les paramètres du modèle (coûteux).
GPUs (Graphics Processing Units) : Processeurs spécialisés essentiels pour l'entraînement et l'inférence des LLM.
GraphRAG : Evolution du RAG utilisant des graphes de connaissances pour améliorer la pertinence (jusqu'à 99% de précision).
Hallucination : Quand un LLM génère des informations factuellement incorrectes avec confiance.
Hyperparamètres : Paramètres de configuration du training (learning rate, batch size, etc.) à ajuster pour optimiser performance.
Inférence : Phase d'utilisation du modèle entraîné pour générer des prédictions/réponses.
Instruction Tuning : Fine-tuning sur des paires instruction/réponse pour améliorer le suivi de consignes.
Knowledge Cutoff : Date limite des connaissances d'un modèle (ex : janvier 2025 pour GPT-5).
Latence : Temps entre l'envoi d'une requête et la réception de la réponse.
LLM (Large Language Model) : Modèle de langage de grande taille (milliards de paramètres) capable de comprendre et générer du texte.
LoRA (Low-Rank Adaptation) : Technique de fine-tuning efficiente ajoutant de petites matrices d'adaptation au lieu de modifier tous les paramètres. Coût divisé par 5-10x vs full fine-tuning.
MoE (Mixture of Experts) : Architecture activant seulement une partie des paramètres par requête pour plus d'efficience (ex : DeepSeek V3).
Overfitting (Surapprentissage) : Quand un modèle apprend par cœur les données d'entraînement au détriment de la généralisation.
Paramètres : Valeurs apprises définissant le comportement du modèle (ex : 7B = 7 milliards de paramètres).
Prompt : Instruction ou question envoyée à un LLM pour obtenir une réponse.
Prompt Engineering : Art d'optimiser la formulation des instructions pour améliorer les réponses du modèle.
QLoRA (Quantized LoRA) : Version ultra-économique de LoRA utilisant la compression 4-bit. Coût : 500€-1500€.
Quantification : Compression du modèle pour réduire son empreinte mémoire et ses coûts d'inférence.
RAG (Retrieval-Augmented Generation) : Architecture connectant un LLM à des bases de connaissances pour récupérer des informations pertinentes en temps réel.
Re-ranking : Ré-ordonnancement des résultats récupérés par RAG pour améliorer la pertinence.
RLHF (Reinforcement Learning from Human Feedback) : Technique d'alignement utilisant du feedback humain pour améliorer le comportement du modèle.
RLAIF (RL from AI Feedback) : Variante utilisant l'IA pour générer le feedback, plus scalable et moins coûteuse.
Semantic Search : Recherche par similarité de sens (vs mots-clés exacts).
Structured Prompting : Technique définissant précisément rôle, contraintes et format attendu dans le prompt.
Supervised Fine-Tuning (SFT) : Fine-tuning sur des données étiquetées avec paires input/output explicites.
Temperature : Paramètre contrôlant le caractère aléatoire des réponses (0 = déterministe, 1 = créatif).
Token : Unité de base du texte pour les LLM (~0,75 mot ou ~4 caractères en moyenne).
Tree of Thought (ToT) : Extension du CoT explorant plusieurs raisonnements en parallèle avant de converger.
Vector Database : Base de données spécialisée pour stocker et rechercher des embeddings (ex : Pinecone, Qdrant, Weaviate).
Zero-Shot Prompting : Donner des instructions précises sans exemples, comptant sur les capacités générales du modèle.
Blog
Contact
contact@iannis.fr
© 2025. All rights reserved.
SUIVEZ-MOI